.png&w=3840&q=75)
Трансформеры сегодня – золотой стандарт нейросетей, и, особенно, больших языковых моделей. Они стали первой по-настоящему масштабируемой архитектурой, то есть с ними впервые стало возможно гарантировано наращивать перформанс моделей за счет увеличения количества данных и параметров, не упираясь в потолок производительности железа или запоминающей способности нейросети.
Именно трансформер изменил индустрию искусственного интеллекта и сделал ее такой мощной, какой мы видим ее сейчас. До 2017 года, пока исследователи из Google Brain не изобрели эту архитектуру, краеугольным камнем ИИ-индустрии был поиск подходящего строения модели. Теперь же перед учеными стоят, в основном, другие задачи, а вот об архитектуре компании и ресерчеры почти не думают: ведь есть трансформер!
Вот так говорит об этой архитектуре знаменитый Андрей Карпаты – бывший ML-директор Tesla, сооснователь и бывший главный ученый OpenAI: "Трансформер - не просто очередной метод, а подход, который полностью изменил наш взгляд на ИИ. Нам очень повезло, что мы наткнулись именно на него в огромном пространстве алгоритмов. Я верю, что трансформер лучше человеческого мозга во многих отношениях."
Однако, несмотря на все свои достоинства, у трансформера есть и недостатки. Поэтому некоторые группы исследователей продолжают искать лучший алгоритм, который мог бы превзойти трансформер или хотя бы достичь его уровня. В этой статье мы разберемся, почему эта задача так нетривиальна, что именно в трансформере оставляет желать лучшего, и какие архитектуры в 2024 году могут посоревноваться с ним за звание серебряной пули глубокого обучения.
Почему трансформеры так сложно заменить
Чтобы разобраться в этом вопросе, давайте нырнем в эту архитектуру глубже. Что вообще представляет из себя трансформер?
Начало трансформерам положила ставшая культовой статья "Attention Is All You Need", выпущенная в 2017 году восемью исследователями Google. При этом все восемь авторов указаны как равноправные участники: это редкость для научных статей. Кстати, ныне никто из этой восьмерки больше не работает в Google. Почти все они стали основателями известных ИИ-стартапов, таких как Cohere, Character.ai, Adept, Inceptive, Essential AI и Sakana AI.
Исторически, до трансформеров главной LLM-архитектурой были рекурретные нейросети (RNN). RNN, а также их продвинутые аналоги LSTM и GRU, обрабатывали информацию последовательно, как человек, который читает слева направо. Тем не менее, относительно манеры человеческого чтения этот алгоритм сильно упрощен. Дело в том, что в основе этих архитектур – скрытое состояние, которое на каждом шаге рекуррентно (отсюда и название механизма) обновляется. Однако, как мы понимаем, связи между словами могут быть и более сложными: например, проявляться не только последовательно. Поэтому обрабатывая слова (а точнее токены) строго один за одним, мы теряем возможность улавливать связи между словами, стоящими не рядом. Ведь модель может просто-напросто успеть "забыть" что-то важное, прежде чем ей выпадет шанс понять, что для дальнейшего текста это было важно.
Поэтому следующей значимой вехой в развитии NLP стал механизм внимания. Традиционно считается, что его изобрел в 2014 году один из отцов глубокого обучения Йошуа Бенджио. Суть механизма заключается в том, что мы "взвешиваем" релевантность всех токенов последовательности относительно друг друга: каждый с каждым. На практике это реализуется как перемножение трех тензоров: Query, Key и Value. Каждая из этих матриц получается в результате умножения входных эмбеддингов X на некоторые обучаемые веса W. Воспринимать Query, Key и Value можно как составляющие, необходимые для "умного поиска" по последовательности: запросы, ключи и значения. При последовательном перемножении этих матриц (как показано на картинке ниже) мы и получаем тот самый attention, который показывает значимость связей между словами. Таким образом, с помощью внимания мы можем учитывать связи между словами в отрывке независимо от того, насколько далеко они находятся друг от друга.
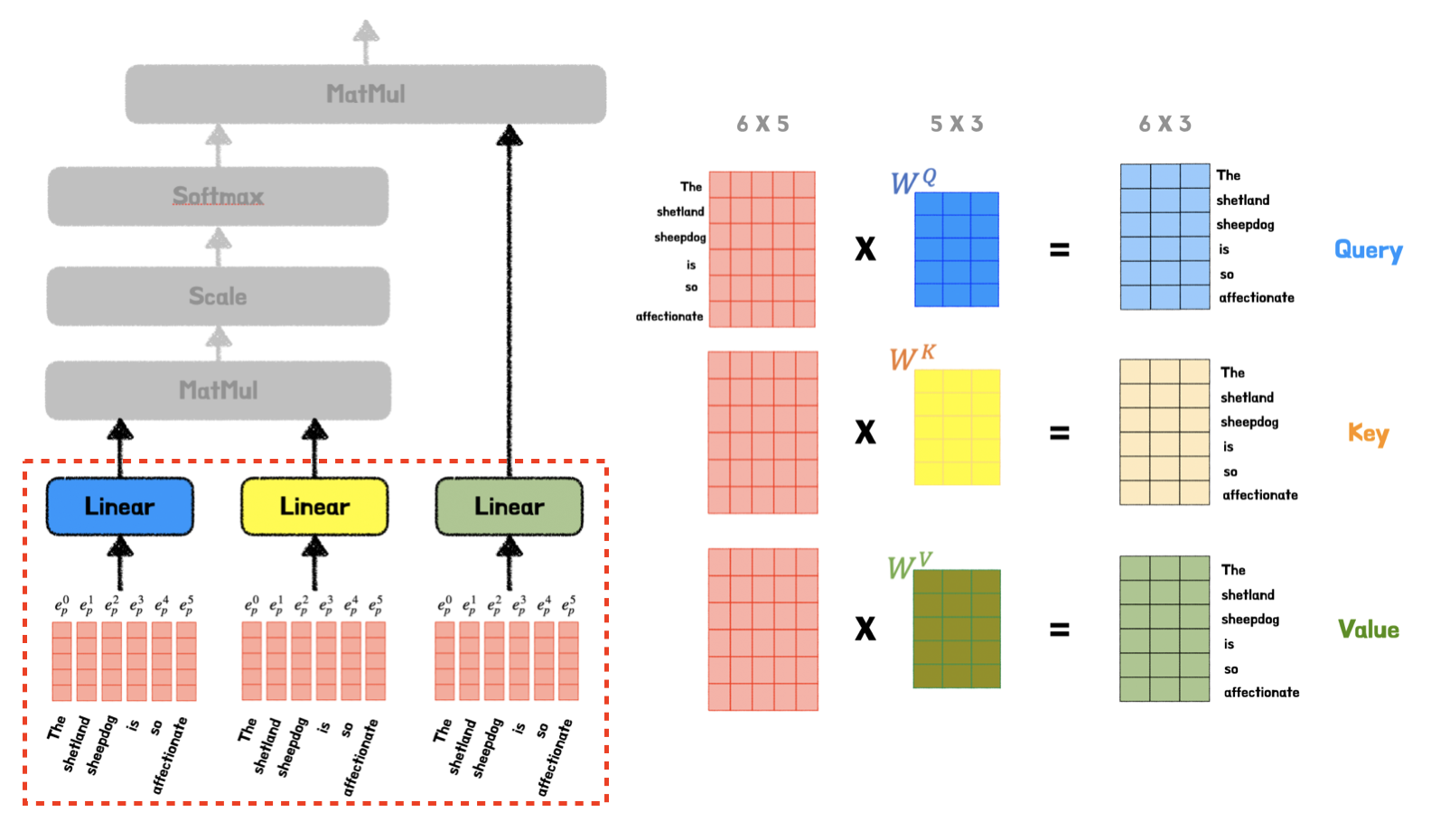 Однако появление механизма внимание самого по себе не произвело революцию в искусственном интеллекте. До статьи о трансформере исследователи использовали attention только как дополнение к архитектуре RNN. Достижение команды Google состояло именно в том, что они изобрели архитектуру, в которой абсолютно отказались от концепции RNN и полностью положились на механизм внимания. Отсюда и название статьи: "Attention Is All You Need" (конечно, и без отсылки к известной песне The Beatles не обошлось). Кстати, устоявшиеся термины Query, Key и Value тоже были введены в этом исследовании. Так родился трансформер, фундаментальным новшеством которого стала возможность обрабатывать последовательности параллельно, а не последовательно. Это дает модели способность не только глобально понимать тексты, которые она читает и пишет, но и эффективно обучаться и масштабироваться. Трансформер может "съесть" тонны информации и разрастаться до огромного количества параметров. При этом его перформанс не выходит на плато, а продолжает расти. Это – еще одна важная отличительная черта этой архитектуры.
Однако появление механизма внимание самого по себе не произвело революцию в искусственном интеллекте. До статьи о трансформере исследователи использовали attention только как дополнение к архитектуре RNN. Достижение команды Google состояло именно в том, что они изобрели архитектуру, в которой абсолютно отказались от концепции RNN и полностью положились на механизм внимания. Отсюда и название статьи: "Attention Is All You Need" (конечно, и без отсылки к известной песне The Beatles не обошлось). Кстати, устоявшиеся термины Query, Key и Value тоже были введены в этом исследовании. Так родился трансформер, фундаментальным новшеством которого стала возможность обрабатывать последовательности параллельно, а не последовательно. Это дает модели способность не только глобально понимать тексты, которые она читает и пишет, но и эффективно обучаться и масштабироваться. Трансформер может "съесть" тонны информации и разрастаться до огромного количества параметров. При этом его перформанс не выходит на плато, а продолжает расти. Это – еще одна важная отличительная черта этой архитектуры. 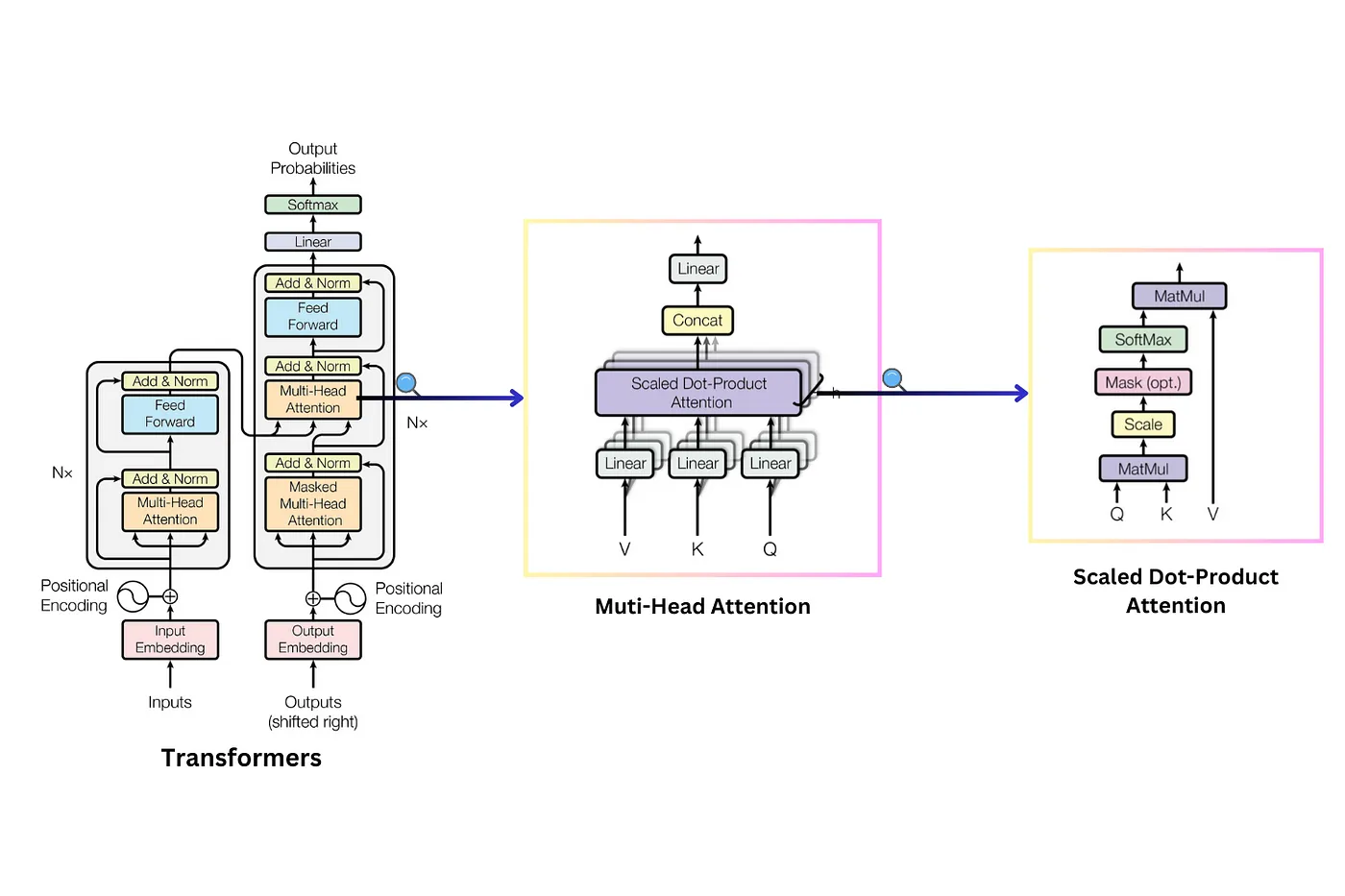 На сегодняшний день трансформеры уже окончательно захватили ИИ-индустрию и ресерч. Все популярные сегодня чатботы — ChatGPT от OpenAI, Gemini от Google, Claude от Anthropic, Grok от xAI — основаны на трансформере. То же самое касается и инструментов для генерации изображений: Midjourney, Stable Diffusion, Runway и так далее. Такие сети построены на основе моделей диффузии, которые внутри себя, в свою очередь, используют трансформеры. Кроме того, архитектуру применяют в моделях предсказания структур молекул, робототехнике и беспилотных автомобилях. Соавтор статьи про трансформер, Ашиш Васвани, удачно высказался про эту модель так: "Трансформер — это способ очень быстро одновременно зафиксировать все связи между различными частями любого ввода. Это могут быть части предложения, ноты, пиксели или молекулы белка. Он подходит для любой задачи."
На сегодняшний день трансформеры уже окончательно захватили ИИ-индустрию и ресерч. Все популярные сегодня чатботы — ChatGPT от OpenAI, Gemini от Google, Claude от Anthropic, Grok от xAI — основаны на трансформере. То же самое касается и инструментов для генерации изображений: Midjourney, Stable Diffusion, Runway и так далее. Такие сети построены на основе моделей диффузии, которые внутри себя, в свою очередь, используют трансформеры. Кроме того, архитектуру применяют в моделях предсказания структур молекул, робототехнике и беспилотных автомобилях. Соавтор статьи про трансформер, Ашиш Васвани, удачно высказался про эту модель так: "Трансформер — это способ очень быстро одновременно зафиксировать все связи между различными частями любого ввода. Это могут быть части предложения, ноты, пиксели или молекулы белка. Он подходит для любой задачи."
Что в трансформерах нас не устраивает
"Если трансформеры такие крутые, то зачем вообще нам какие-то альтернативы?" – спросите вы.
Да, трансформеры хороши, но и у них есть проблемы. В частности, в предыдущем разделе мы разобрали, что для того, чтобы вычислить внимание, каждый токен должен быть взвешен относительно каждого другого, и это приводит к квадратичной сложности операций. Более того, чтобы во время декодирования избежать пересчета матриц всех ключей и значений, их приходится хранить. Для этого используется так называемый key-value cache, и, очевидно, памяти он занимает немало. Трансформеры действительно ненасытны: обучение передовой большой языковой модели сегодня подразумевает круглосуточную работу тысяч графических процессоров в течение нескольких месяцев. Именно на эти нужды стартапы привлекают миллиарды долларов финансирования. Иногда затраты на обучение LLM превышают бюджеты целых стран. Таким образом, тонкая восприимчивость к контексту, которая делает трансформеры такими "умными", также является главной слабостью этой архитектуры.
Кроме того, получается, что архитектура трансформера масштабируется квадратично по мере увеличения длины последовательности. То есть, когда длина последовательности, обрабатываемой трансформером (скажем, количество слов в отрывке), увеличивается на заданную величину, требуемые для обработки вычисления увеличиваются на эту величину в квадрате и быстро становятся неподъемно огромными. Это приводит к проблеме невозможности увеличения контекстного окна. Это очень важно, потому что сильно ограничивает способность трансформера работать, например, с большой базой данных, или с большим кодовым проектом, или с длинными последовательностями геномов.
А еще трансформеры часто склонны аллоцировать внимание на нерелевантный контекст. Именно это приводит к тому, что мы называем галлюцинациями. При этом исправлять ошибки, которые допускают трансформеры, да и даже просто анализировать их – непростая задача, ведь это большие черные ящики. Это подсвечивает еще одну проблему архитектуры – проблему отсутствия интерпретируемости, которая так важна для применения LLM в реальной жизни (особенно в бизнесе).
Все эти недостатки открывают двери для возможного появления новых и улучшенных архитектур глубокого обучения. За последние годы многие исследовательские группы предпринимали попытки нащупать альтернативу этому золотому стандарту. И, хотя с железного трона трансформеры так никто и не сместил, но конкуренты у них успели появиться.
Небольшие модификации трансформера
Конечно, не обязательно сразу брать и изобретать что-то принципиально новое: с 2017 года было предложено множество вариантов и модификаций классического трансформера, и, в частности, механизма внимания.
Например, Group-Query attention – что-то среднее между классическим multi-head attention (MHA) и максимально упрощенным, но бодрым multi-query attention (MQA). MHA – метод, который был предложен в оригинальной статье. Он предполагает, что вместо вычисления внимания один раз, мы создаем для каждого батча несколько вариантов запросов, ключей и значений и вычисляем внимание много раз параллельно. Так формируются подпространства представлений, которые даруют модели способность фокусироваться на разных аспектах входной информации. Метод эффективный, но дорогой. Multi-query attention было попыткой повторить успех MHA, но сделать алгоритм менее затратным. Здесь мы параллельно вычисляем только запросы, а ключи и значения сохраняем для каждой головы неизменными. Таким образом, вычисления становятся дешевле. Однако тут с эффективностью, как говорится, переборщили: MQA показывает себя намного слабее MHA. Вот и придумали "золотую середину": Group-Query attention. Этот механизм группирует некоторое количество запросов и сопоставляет каждой группе свои ключи и значения. Получается, что и в качестве мы не очень теряем, и эффективность инференса повышаем. 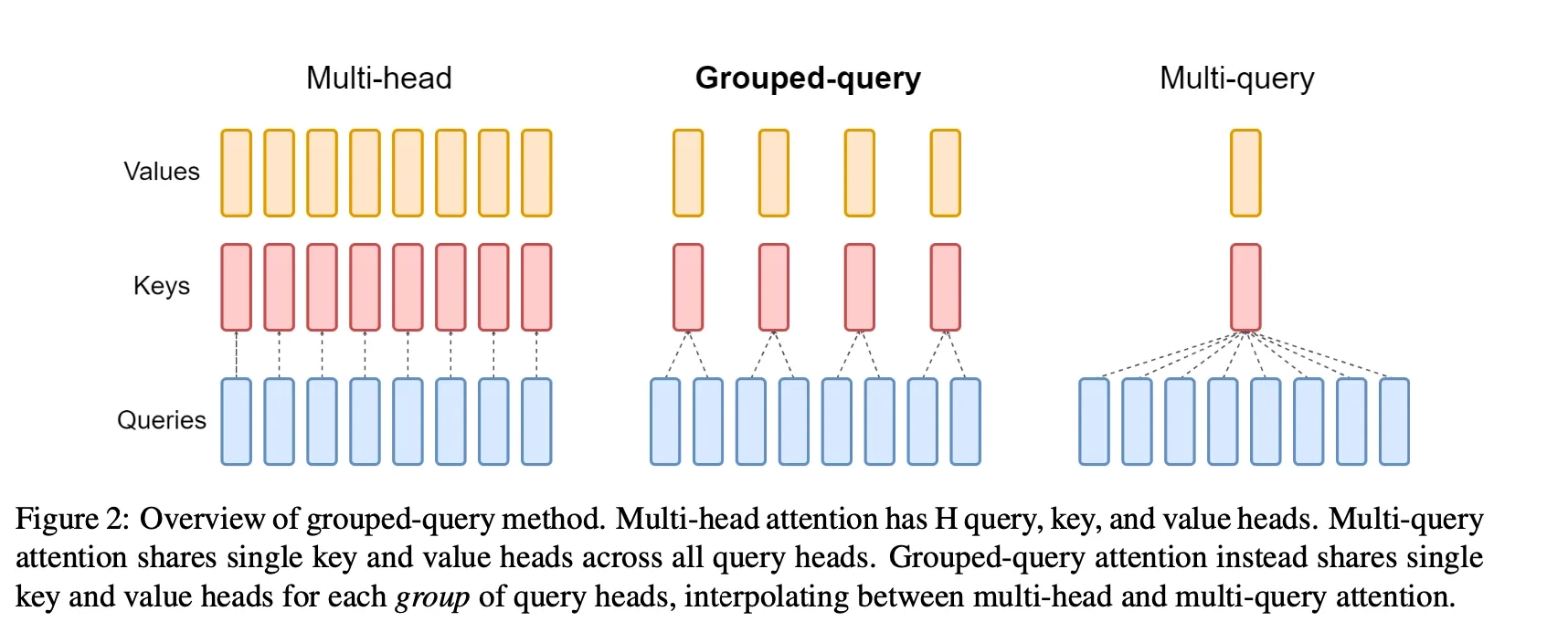 Также стоит упомянуть Random-feature-based attention (RFA). Этот метод предлагает линейный механизм внимания. При этом линейным он становится не за счет сокращения голов внимания или KV-кэша, а за счет хитрой аппроксимации функции softmax. Этот алгоритм, кстати, еще несколько раз пытались докрутить другие ученые: было даже доказано, что оригинальный softmax можно полностью восстановить из аппроксимированного attention. Правда, это достаточно сложно и требует дополнительных вычислений, так что исходная идея оптимизации немного страдает. А два года назад исследователи даже предложили трансформер без механизма внимания вообще (Attention Free Transformer). В нем все матричные умножения, которые тянут на себя основные квадратичные вычисления, заменены на поэлементные. К сожалению, оба описанных метода еще не до конца изучены: в частности, неполностью доказана их эффективность относительно ванильного внимания. Поэтому и RFA, и AFT все еще почти не используются в продакшене.
Также стоит упомянуть Random-feature-based attention (RFA). Этот метод предлагает линейный механизм внимания. При этом линейным он становится не за счет сокращения голов внимания или KV-кэша, а за счет хитрой аппроксимации функции softmax. Этот алгоритм, кстати, еще несколько раз пытались докрутить другие ученые: было даже доказано, что оригинальный softmax можно полностью восстановить из аппроксимированного attention. Правда, это достаточно сложно и требует дополнительных вычислений, так что исходная идея оптимизации немного страдает. А два года назад исследователи даже предложили трансформер без механизма внимания вообще (Attention Free Transformer). В нем все матричные умножения, которые тянут на себя основные квадратичные вычисления, заменены на поэлементные. К сожалению, оба описанных метода еще не до конца изучены: в частности, неполностью доказана их эффективность относительно ванильного внимания. Поэтому и RFA, и AFT все еще почти не используются в продакшене.
То же самое можно сказать и о таких модификациях, как Longformer, Reformer, Performer, Linformer и Big Bird. Каждая из этих версий предлагает какие-то менее прожорливые варианты трансформера или варианты для работы с длинными последовательностями, но, как правило, все эти архитектуры жертвуют перформансом и метриками, и поэтому не смогли получить распространение.
А вот FlashAttention в современных моделях используют активно. Правда, в нем никаких алгоритмических уловок нет: это скорее оптимизированные аппаратные возможности железа, которые делают механизм внимания более эффективным, не меняя его основную суть.
Из недавнего, интересную модификацию внимания также предложили в Microsoft. Как мы уже упоминали, что трансформеры склонны аллоцировать внимание на нерелевантный контекст (это называют шумом), и это приводит к проблемам с извлечением информации и, как следствие, к галлюцинациям и потерям в точности. Microsoft предложили изящное решение: для каждой головы внимания вместо одной attention мапы они создают две, дублируя keys и queries, а затем вычитают их друг из друга. Тем самым шумы нивелируют друг друга в attention scores – это похоже на реализацию балансного усилителя в радиотехнике. Такой подход не делает внимание эффективнее, но зато сразу повышает аттеншен к релевантным деталям: эксперименты показали, что трансформеры с таким diff вниманием лучше обычных справляются с задачами на длинном контексте. Кроме того, подход еще и уменьшает количество выбросов в активациях модели, что упрощает ее квантование.
Но, конечно, разные варианты аттеншена – это не все, что придумали ученые за семь лет. Есть и более новые архитектуры. Правда, иногда новое – это хорошо забытое старое.
RNN и компания
RNN были предшественниками трансформеров. Мы уже упоминали, что у них есть существенные недостатки: они не поддаются параллелизации и обрабатывают токены строго друг за другом, из-за чего могу терять существенные смысловые связи. Тем не менее, RNN показывали себя довольно хорошо, и даже сейчас архитектуры-конкуренты трансформера часто основываются именно на идеях рекурретных сетей. Главное, чем они притягивают исследователей, – это линейная сложность операций. Относительно запросов трансформеров RNN – просто скромницы. Вот их и пытаются как-то дотянуть до мощностей трансформера, чтобы итоговая модель сочетала в себе и вычислительную эффективность, и широкие “интеллектуальные способности”.
Давайте вспомним, что представляет из себя оригинальная архитектура RNN. На самом деле, в ее основе лежит незамысловатая идея: модель выглядит как цепочка одинаковых блоков, и при обработке очередного токена обращается к предыдущим, как к контексту. Это происходит благодаря обновлению так называемых hidden states: на каждом шаге в сеть подаются данные (эмбеддинг очередного токена), при этом рекуррентно происходит обновление скрытого состояния. На вход очередному кирпичику каждый раз поступает не только новый токен, но и некоторая информация о контексте, передающаяся из предыдущих ячеек. После этого по скрытому состоянию предсказывается выходной сигнал.
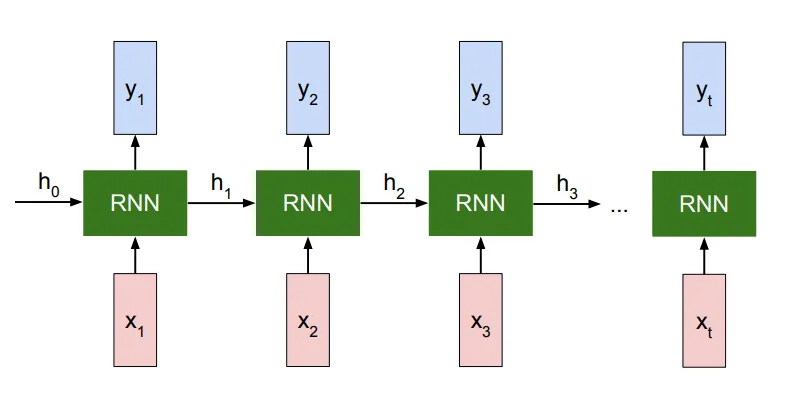
В RNN очень часто приходится сталкиваться с проблемой взрыва и затухания градиентов, поэтому на практике более известна другая рекурретная архитектура – LSTM. Архитектура LSTM была предложена в 1997 году немецкими исследователями Зеппом Хохрайтером и Юргеном Шмидхубером. С тех пор она выдержала испытание временем: с ней связано много прорывов в глубоком обучении, в частности именно LSTM стали первыми большими языковыми моделями. В отличие от RNN, в LSTM, помимо скрытого состояния, появляется также состояние ячейки и гейты, с помощью которых мы контролируем, какую информацию мы оставляем или удаляем из памяти. 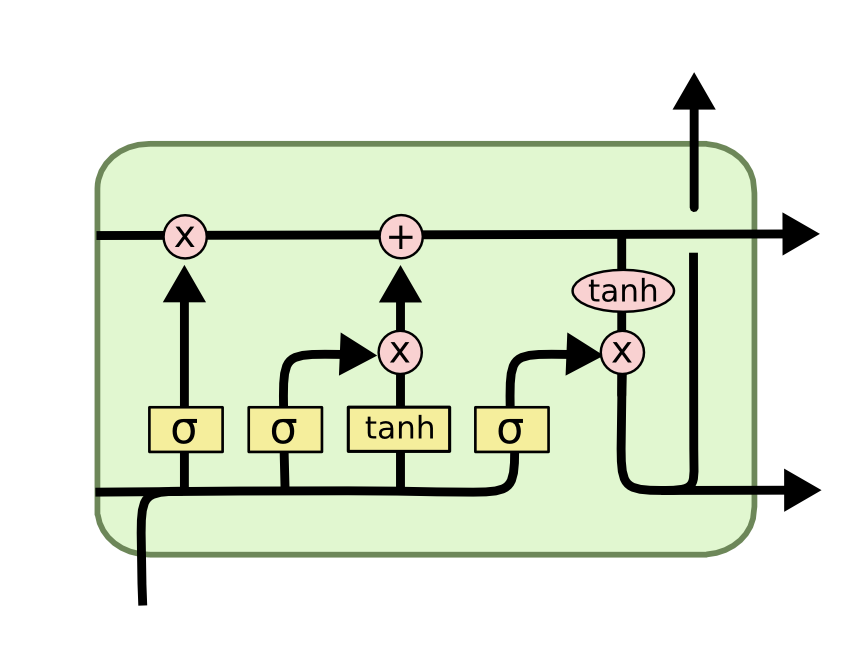 Архитектура, хоть и выглядит сложной и перегруженной, действительно работает на ура. Правда, у нее все же есть несколько проблем, из-за которых ее и победили в 2017 году трансформеры. Во-первых, это ограниченная способность пересматривать решения о хранении информации. То есть, если сеть с помощью своих гейтов забыла какую-то информацию или, наоборот, запомнила ее как очень важную, то затем это решение сложно корректировать. Во-вторых, чересчур сильное сжатие данных (ведь память у LSTM скалярна). В-третьих, как и в любых RNN, в LSTM невозможно распараллелить вычисления, поэтому LSTM считается плохо масштабируемой архитектурой.
Архитектура, хоть и выглядит сложной и перегруженной, действительно работает на ура. Правда, у нее все же есть несколько проблем, из-за которых ее и победили в 2017 году трансформеры. Во-первых, это ограниченная способность пересматривать решения о хранении информации. То есть, если сеть с помощью своих гейтов забыла какую-то информацию или, наоборот, запомнила ее как очень важную, то затем это решение сложно корректировать. Во-вторых, чересчур сильное сжатие данных (ведь память у LSTM скалярна). В-третьих, как и в любых RNN, в LSTM невозможно распараллелить вычисления, поэтому LSTM считается плохо масштабируемой архитектурой.
Но что, если попытаться обойти эти ограничения? Может ли тогда LSTM снова стать альтернативой трансформеру?
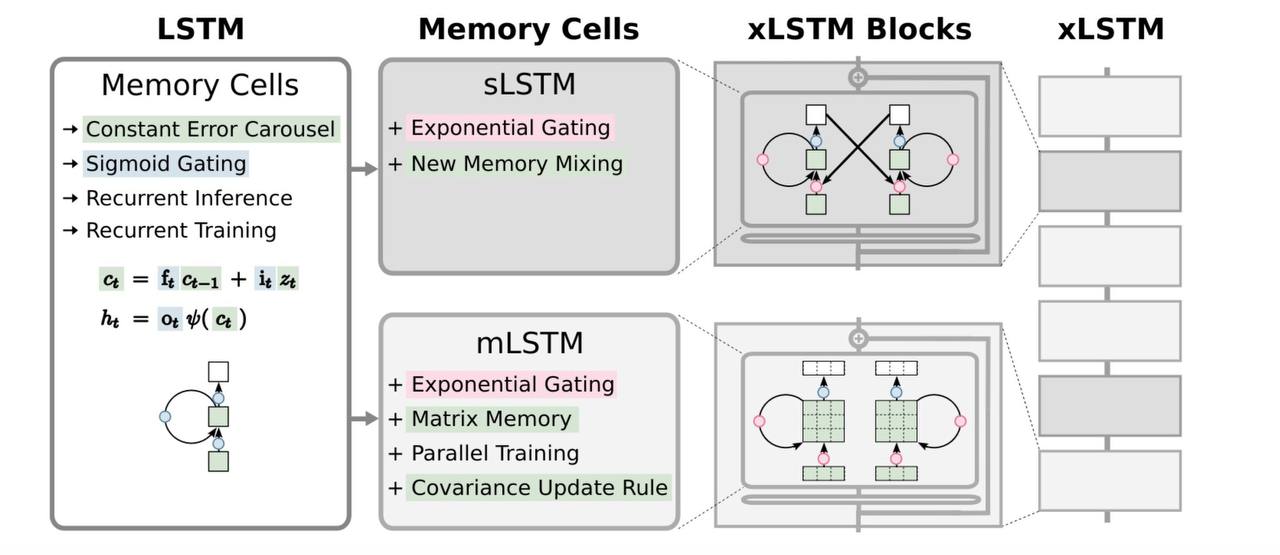
Возможно. По крайней мере, исследования на эту тему действительно ведутся. Например, недавно, спустя 27 лет, создатели LSTM предложили улучшение своей технологии – xLSTM. Благодаря нововведениям xLSTM может теперь конкурировать с трансформерами и по перформансу, и по масштабируемости. В новую модель внедрили экспоненциальные гейты вместо сигмоидальных, новый алгоритм смешивания памяти, матричную память вместо скалярной и альтернативное правило обновления ковариаций. Вообще, xLSTM состоит из mLSTM и sLSTM. В mLSTM память это больше не скаляр, а матрица, что расширяет возможности сетки хранить информацию и позволяет параллелить обучение. А в sLSTM зашит новый метод смешивания памяти. Чтобы получилась xLSTM, эти два вида блоков затем оборачиваются в residual слои и состыковываются друг с другом. Об этой архитектуре, кстати, мы делали отдельный большой разбор.
 LSTM пытались менять и другими способами. Например, в недавней громкой статье "Were RNNs All We Needed?" ученые предложили подружить рекуррентные сети с известным алгоритмом Parallel Scan, который позволяет за логарифм от длины последовательности посчитать все префиксные суммы. Для этого они модифицируют LSTM так, чтобы все операции в ней были ассоциативны (это когда (a+b) + c = a + (b+c)). Получившуюся minLSTM, как оказалось, можно эффективно параллелить. От этого, конечно, снова частично теряется предсказательная сила модели, однако исследование все-равно интересное.
LSTM пытались менять и другими способами. Например, в недавней громкой статье "Were RNNs All We Needed?" ученые предложили подружить рекуррентные сети с известным алгоритмом Parallel Scan, который позволяет за логарифм от длины последовательности посчитать все префиксные суммы. Для этого они модифицируют LSTM так, чтобы все операции в ней были ассоциативны (это когда (a+b) + c = a + (b+c)). Получившуюся minLSTM, как оказалось, можно эффективно параллелить. От этого, конечно, снова частично теряется предсказательная сила модели, однако исследование все-равно интересное.
 Стоит также упомянуть, что совсем недавно у исследователей из из Стэнфорда, Беркли, Сан-Диего и Meta AI вышла статья про Test-Time Training RNN. В этой модели ученые заменяют скрытое состояние RNN моделью машинного обучения, которая сжимает контекст посредством фактического градиентного спуска по входным токенам. Авторы назвали это Test-Time-Training слоями. TTT слои напрямую заменяют внимание и фактически дарят нам архитектуру линейной сложности с гибкой памятью. При этом вместо того, чтобы хранить контекст в фиксированном состоянии, после прямого прохода по последовательности состояние «обучается» на токенах контекстного окна. При этом скрытое состояние находится только в одном слое общей архитектуры. Остальные компоненты, например, матрицы QKV, обучаются на этапе предобучения с помощью стандартной кросс-энтропии. Получается своеобразное мета-обучение: авторы прозвали это Learning to Learn at Test Time. Конечная архитектура как бы обучается находить лучший способ сжатия контекста, чтобы добиться лучшего качества в предсказании следующего токена. Сейчас архитектуру продолжают изучать, и результаты многообещающие: по перплексии модели, реализованные в статье соответствуют трансформерам и Mamba (об этой модели мы поговорим позже). При этом TTT-Linear быстрее, чем самые быстрые SSM, и имеет бодрые способности к масштабированию по размеру и длине контекста.
Стоит также упомянуть, что совсем недавно у исследователей из из Стэнфорда, Беркли, Сан-Диего и Meta AI вышла статья про Test-Time Training RNN. В этой модели ученые заменяют скрытое состояние RNN моделью машинного обучения, которая сжимает контекст посредством фактического градиентного спуска по входным токенам. Авторы назвали это Test-Time-Training слоями. TTT слои напрямую заменяют внимание и фактически дарят нам архитектуру линейной сложности с гибкой памятью. При этом вместо того, чтобы хранить контекст в фиксированном состоянии, после прямого прохода по последовательности состояние «обучается» на токенах контекстного окна. При этом скрытое состояние находится только в одном слое общей архитектуры. Остальные компоненты, например, матрицы QKV, обучаются на этапе предобучения с помощью стандартной кросс-энтропии. Получается своеобразное мета-обучение: авторы прозвали это Learning to Learn at Test Time. Конечная архитектура как бы обучается находить лучший способ сжатия контекста, чтобы добиться лучшего качества в предсказании следующего токена. Сейчас архитектуру продолжают изучать, и результаты многообещающие: по перплексии модели, реализованные в статье соответствуют трансформерам и Mamba (об этой модели мы поговорим позже). При этом TTT-Linear быстрее, чем самые быстрые SSM, и имеет бодрые способности к масштабированию по размеру и длине контекста.
 Исследования также ведутся и "с другого берега", когда за основу берут не RNN, а трансформер, в который уже пытаются вростить какие-то полезные свойства рекурретных сетей. В 2023, в частности, появились целых две подобные архитектуры, которые нельзя не упомянуть: RWKV и RetNet.
Исследования также ведутся и "с другого берега", когда за основу берут не RNN, а трансформер, в который уже пытаются вростить какие-то полезные свойства рекурретных сетей. В 2023, в частности, появились целых две подобные архитектуры, которые нельзя не упомянуть: RWKV и RetNet.
В RWKV (Receptance Weighted Key Value) рекурретные блоки занимают место слоев внимания. Из трансформера здесь позаимствованы ключи и значения (Key Value), но никакого скалярного произведение между ними нет. Вместо этого в сеть добавляются тензоры Receptance и Weight – аналоги скрытого состояния и гейта забывания из RNN, которые специальным образом обновляются, подобно тому, как это происходит в LSTM. При этом общая архитектура все-же больше напоминает трансформер, и за счет этого сохраняет способность к распараллеливанию, не вырождаясь в квадратичные вычисления. Эта модель продолжает развиваться и расти. Уже есть даже полноценные LLM, основанные на этой архитектуре, и с ними можно поэкспериментировать на официальном сайте.
 RetNet (Retentive Network) – архитектура не менее известная. В работе сохраняют поблочную структуру модели, и вместо внимания также используют Retention – версию RNN c обновляемым вектором состояния, где каждое последующее состояние получается как взвешенная сумма прошлого состояния и текущего элемента последовательности. В этой работе реализовано несколько проекций состояния, и все вместе они заменяют query, key, value проекций в attention. Ученые громко заявляют, что RetNet – это быстро, параллельно и качественно, однако архитектура молодая, и исследования по ней еще ведутся.
RetNet (Retentive Network) – архитектура не менее известная. В работе сохраняют поблочную структуру модели, и вместо внимания также используют Retention – версию RNN c обновляемым вектором состояния, где каждое последующее состояние получается как взвешенная сумма прошлого состояния и текущего элемента последовательности. В этой работе реализовано несколько проекций состояния, и все вместе они заменяют query, key, value проекций в attention. Ученые громко заявляют, что RetNet – это быстро, параллельно и качественно, однако архитектура молодая, и исследования по ней еще ведутся.
State space models
Итак, главный недостаток RNN – это неспособность долго хранить информацию и обновлять ее иначе, как рекуррентно. Короче говоря, RNN забывчивы.
Для того, чтобы побороть эту проблему забывания, исследователи в наши дни часто используют алгоритм, который был придуман еще в 60-е: так называемые State Space Models. Исконно они использовались для моделирования непрерывных во времени процессов и описывались системой дифференциальных уравнений следующего вида:
x(t) здесь – аналог скрытого состояния из RNN, u(t) – просто входные данные, а y(t) – аутпуты. Все коэффициенты (A,B,C,D) можно сразу воспринимать как обучаемые матрицы весов, но отвечают они за разные вещи: A(t) – за обновление памяти, B(t) – за преобразование входов, C(t) – за преобразование выходов, а D(t) – это некоторый аналог skip connection (подробнее о skip connection – в этой нашей статье). Вот понятная схема системы, которую описывают эти диффуры: 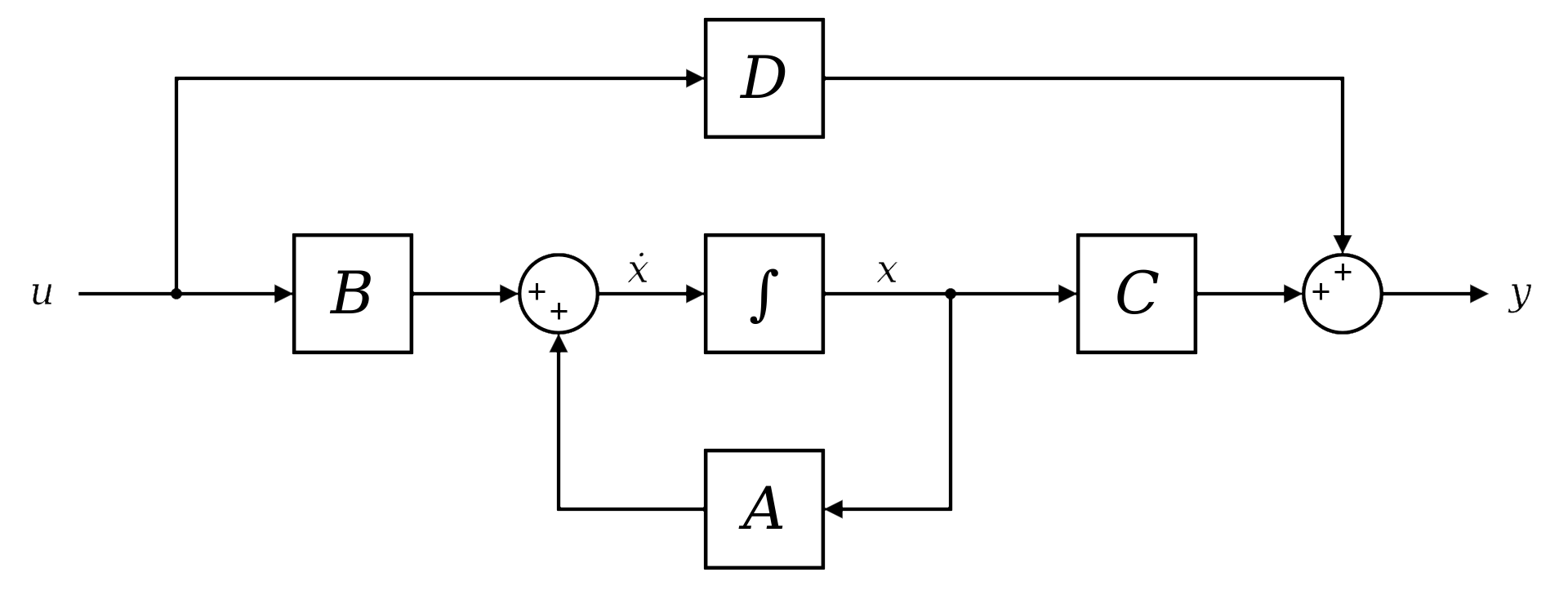 Получается, что:
Получается, что:
- Входные данные поступают в сеть и умножаются на матрицу
B. Таким образом мы решаем, насколько сильно входные данные будут влиять на дальнейшие процессы. Это очень похоже на гейт входного состояния в LSTM. - Далее происходит обновление памяти (aka скрытого состояния). Для этого предыдущее скрытое состояние мы умножаем на матрицу
A. - Затем – аналог гейта выходного состояния: умножение на матрицу
C, которая переводит полученное скрытое состояния в выходной сигнал. - И, наконец, Skip Connection – "перекидывание" оригинального входного сигнала прямо в выходной с некоторым весом (матрица
D). Это очень популярный способ борьбы с проблемой затухания градиентов в сети. Вообще, SC был изобретен еще примерно в 2014 году, но ценить его мы научились совсем недавно.
Внимательный читатель мог заметить, что все, что мы описываем, работает только для непрерывных систем, а нейросети – это системы дискретные. Чтобы обойти это ограничение, в SSM добавляют Zero-order hold. Это, фактически, искусственное удержание входного сигнала на время, пока не поступят новые данные. Такая уловка позволяет перейти от дифференциальных уравнений, описывающих преобразование функций, к системе, которая описывает преобразование последовательностей.
Эта модель – не просто умный аналог RNN. Ее прелесть в том, что она построена на стыке двух мощных архитектур: сверточных нейросетей и рекуррентных. Да, свертки здесь видны не сразу, но они есть: дело в том, что все обучаемые параметры можно собрать в единое ядро и использовать его для свертки. Получается, что мы можем использовать все плюсы рекуррентных нейронных сетей, но при этом представлять их как сверточные, которые в свою очередь... можно распараллелить!
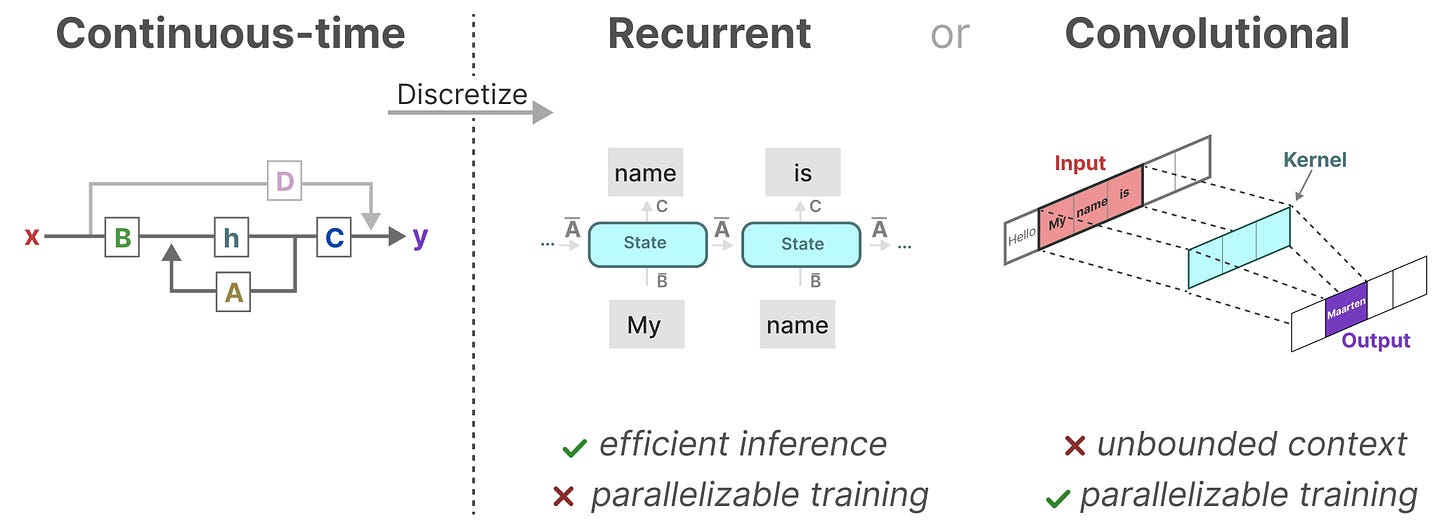 При этом нужно заметить, что в скорости инференса при переходе на CNN мы немного теряем. Но эту проблему исследователи разрешили гениально. Просто во время обучения используется сверточное представления, а во время инференса – рекуррентное.
При этом нужно заметить, что в скорости инференса при переходе на CNN мы немного теряем. Но эту проблему исследователи разрешили гениально. Просто во время обучения используется сверточное представления, а во время инференса – рекуррентное.
На механике SSM построено множество полноценных сильных архитектур. Самые значимые из них – Mamba, Mamba-2, H3, Hawk, Hyena. Каждая из них предлагает собственные надстройки над SSM: например, в легендарной Mamba исследователи добавили в модель алгоритм селективного сканирования для фильтрации нерелевантной информации и метод, позволяющий эффективно хранить на железе промежуточные результаты вычислений.
Самое главное: эти модели действительно могут соревноваться с трансформерами! Например, известный стартап Mistral недавно выпустил модель Codestral, в основе которой – Mamba. На метриках модель показала себя очень неплохо, а еще вместила в себя довольно большой контекст в 256к токенов.
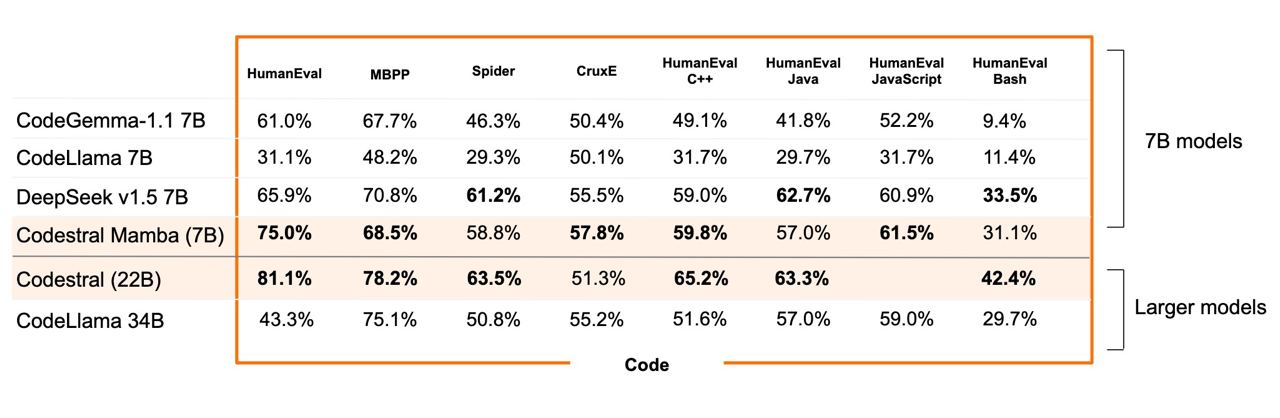 У других стартапов тоже часто мелькают эксперименты с этими алгоритмами. Когда-то даже ходили слухи, что OpenAI используют в своей GPT-4o одну из популярных гибридных архитектур на основе Mamba и трансформера.
У других стартапов тоже часто мелькают эксперименты с этими алгоритмами. Когда-то даже ходили слухи, что OpenAI используют в своей GPT-4o одну из популярных гибридных архитектур на основе Mamba и трансформера.
Конечно, SSM изучены еще не до конца, но вызов трансформерам точно бросить могут. Основное различие между трансформером и SSM заключается в том, что трансформер "сканирует" последовательность полностью, то есть как бы бездумно, а, например, Mamba более избирательно фокусируется только на важном, за счет чего работает эффективнее.
Другие наследники трона
SSM – не единственная наша надежда на будущее. Нельзя не упомянуть квантовые модели, модели на основе ДНК, Meta-Learning и ликдидные архитектуры, которые в последнее время обсуждаются все больше и больше.
Конечно, вытеснить трансформеры не так уж просто. Это исключительно мощная архитектура ИИ. Каждый исследователь привык работать с ней. За последние 5-7 лет тысячи ресерчеров шлифовали, улучшали и оптимизировали трансформеры, и это дает им мощное преимущество. Тем не менее, эта тенденция к унификации, стремление к «одной единственной архитектуре ИИ, которая будет править всеми» — не может продолжаться бесконечно. Более возможен другой сценарий: границы будут расширяться, и мы разработаем или разовьем новые архитектуры, каждая из которых будет заточена под определенный домен. Или, возможно, найдем новый алгоритм, который превзойдет и заменит трансформеры везде.
Одно можно сказать наверняка: сфера искусственного интеллекта сегодня развивается настолько быстро, что не следует ничего воспринимать, как должное. Нас ждет еще много сюрпризов и перемен.