
Архитектура LSTM была предложена в 1997 году немецкими исследователями Зеппом Хохрайтером и Юргеном Шмидхубером. С тех пор она выдержала испытание временем: с ней связано много прорывов в глубоком обучении, в частности именно LSTM стали первыми большими языковыми моделями.
Однако появление трансформеров в 2017 году ознаменовало новую эру, и популярность LSTM пошла на спад. Трансформеры оказались более масштабируемой архитектурой, к тому же способной хранить гораздо больше информации.
Однако на днях, спустя 27 лет, создатели LSTM предложили улучшение своей технологии – xLSTM. Благодаря нововведениям xLSTM может теперь конкурировать с трансформерами и по перформансу, и по масштабируемости.
Как ученые этого добились? Внедрили экспоненциальные гейты вместо сигмоидальных, новый алгоритм смешивания памяти, матричную память вместо скалярной и альтернативное правило обновления ковариаций.
Да, звучит непонятно, но сейчас мы со всем разберемся: эта статья про то, как понять xLSTM и не сойти с ума!
Как работает обычная LSTM?
LSTM – это рекуррентная нейросеть, то есть нейросеть, которая работает с объектами (текстом, действиями пользователя или чем-то другим) последовательно. Такие сети состоят из цепочки одинаковых блоков, и при обработке очередного токена обращаются к предыдущим, как к контексту.
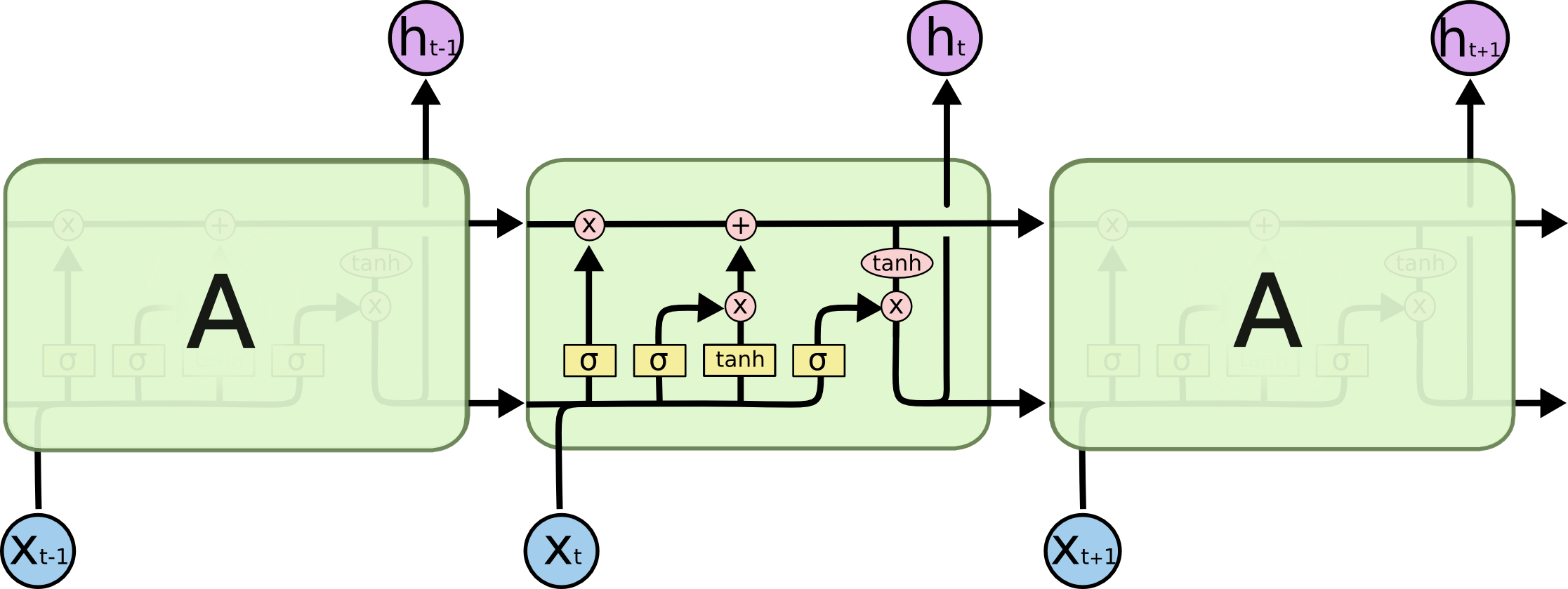 На картинке сверху мы видим как раз такие повторяющиеся блоки LSTM. На вход очередному кирпичику каждый раз поступает не только новый токен, но и некоторая информация о контексте, передающаяся из предыдущих ячеек. Но что за сложная структура внутри блока?
На картинке сверху мы видим как раз такие повторяющиеся блоки LSTM. На вход очередному кирпичику каждый раз поступает не только новый токен, но и некоторая информация о контексте, передающаяся из предыдущих ячеек. Но что за сложная структура внутри блока?
Тут есть несколько основных элементов:
- Скрытое состояние (ht). Это внутренняя память сети, которая передается от слоя к слою.
- Состояние ячейки (ct). Это внутренняя информации LSTM-блока, с помощью которой формируется скрытое состояние.
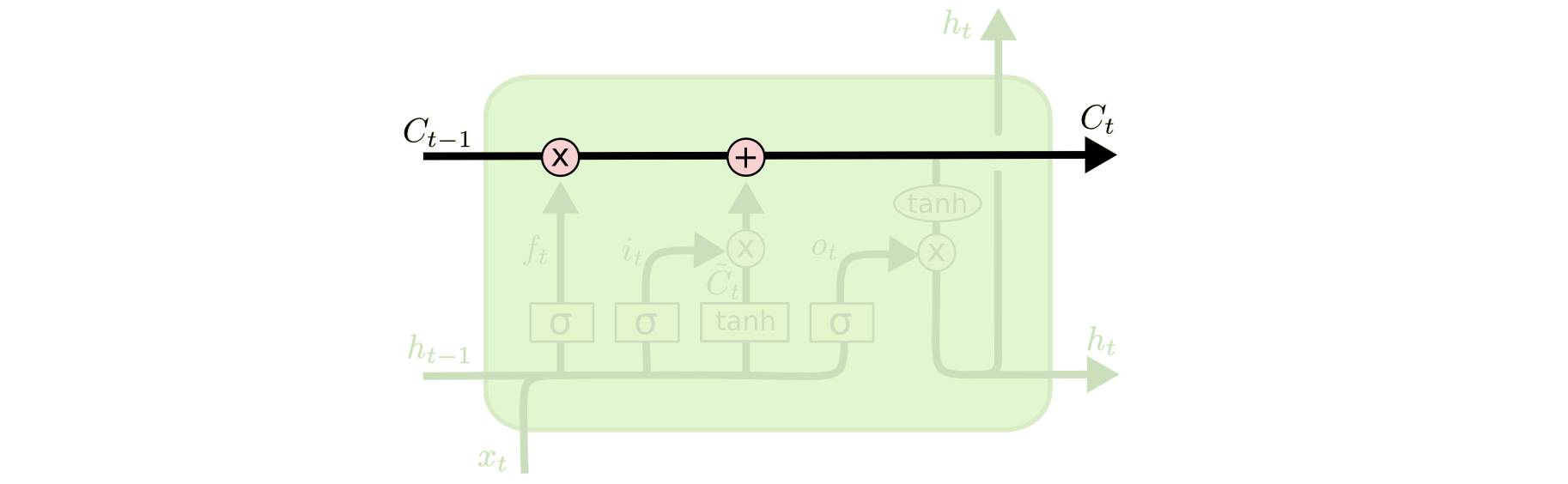
- Гейты, с помощью которых мы контролируем, какую информацию мы оставляем или удаляем из памяти. Их будет три: гейт забывания, гейт входного состояния и гейт выходного состояния.
Теперь, когда мы определились с терминами, давайте пройдемся по блоку LSTM шаг за шагом.
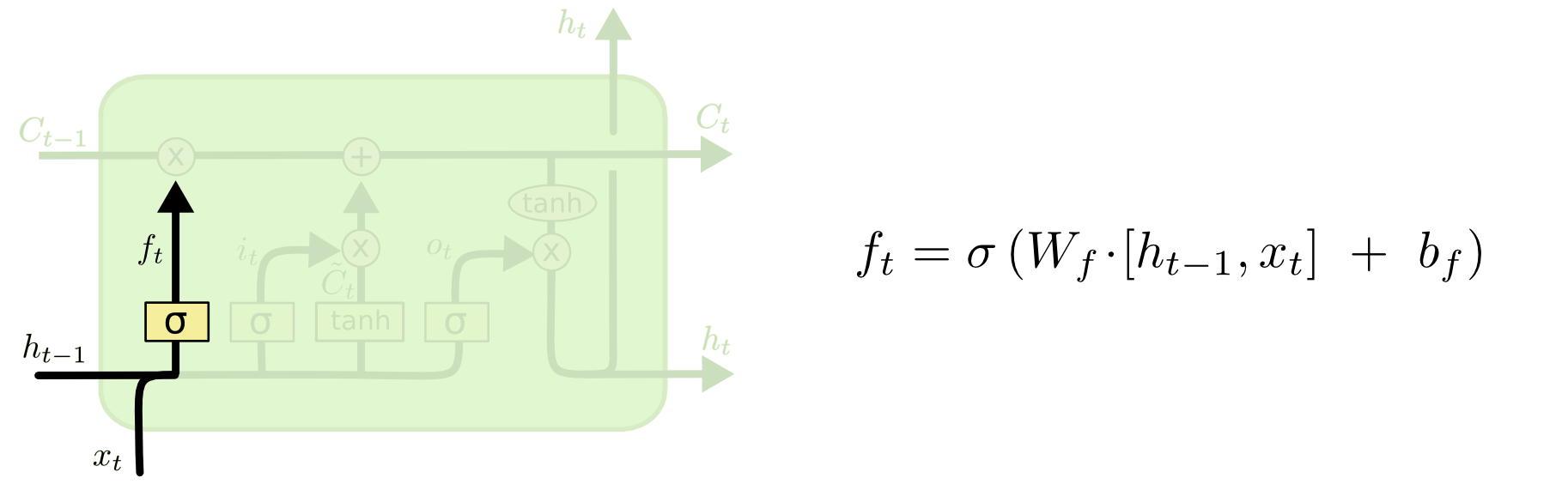
- Перво-наперво блок должен на основе предыдущего скрытого состояния ht-1 и нового поступившего токена xt "решить", какую информацию из предыдущего состояния ячейки Ct-1 он пропустит дальше, а какую забудет. Для этого отрабатывает так называемый "гейт забывания". Он состоит всего из одного сигмоидального слоя, который сопоставляет каждой компоненте вектора информации число от 0 до 1, где 1 – это "пропустить полностью", а 0 - "забыть полностью" (см. формулу ниже).
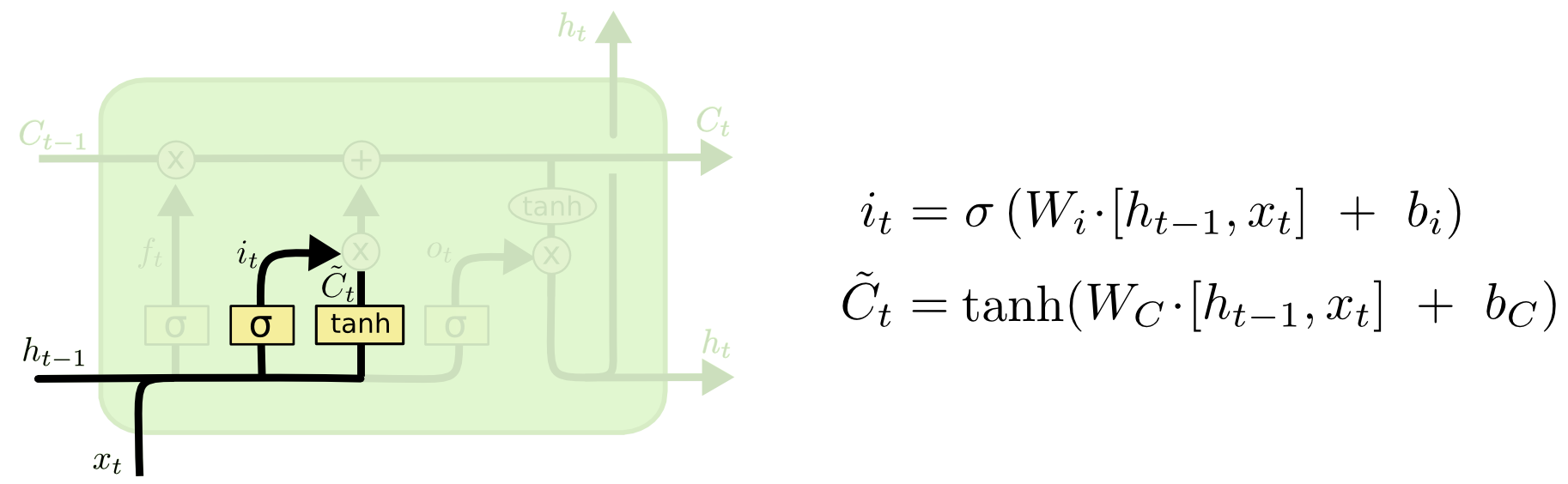
- Следующий шаг – решить, какую новую информацию из поступившего токена xt и предыдущего скрытого состояния ht-1 мы добавим в состояние блока. Для этого открывается следующий гейт – гейт входного состояния. Здесь можно было бы добавить в Ct-1 обычную линейную комбинацию xt и ht-1, к которой применена функция активации tanh (cм. формулу 2 на картинке ниже). Но мы не уверены, что вся эта информация достаточно релевантна, и хотим взять только некоторую ее долю. Чтобы понять, какую именно, с помощью сигмоиды снова вычисляется вектор "забывания", который состоит из чисел от 0 до 1 (cм. формулу 1 на картинке ниже).
- Вычисляем новое состояние ячейки Ct. После применения гейта забывания и гейта входного состояния оно будет равно сумме произведений сигмоидальных векторов ft и it на информацию Ct-1 и Ĉt (см. формулу ниже).
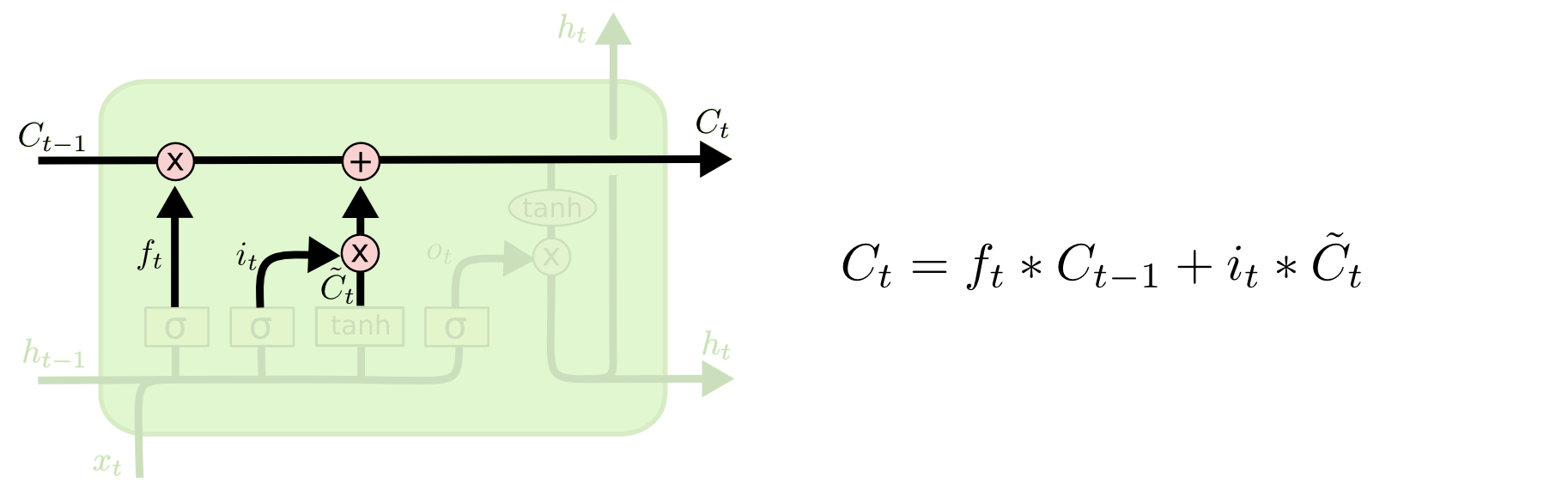
- Осталось только одно – вычислить скрытое состояние ht, которое играет роль выходного вектора LSTM-блока. Оно вычисляется из только что сформированного сетью состояния ячейки Ct с помощью гейта выходного состояния. Работает аналогично другим гейтам: у нас есть Ct, к которому мы применили функцию активации tanh, и на основе xt и ht-1 мы составляем сигмоидальный вектор (см. формулу 1 внизу) чтобы решить, какую часть информации из tanh(Ct) мы отнесем в скрытое состояние ht (см. формулу 2 внизу).
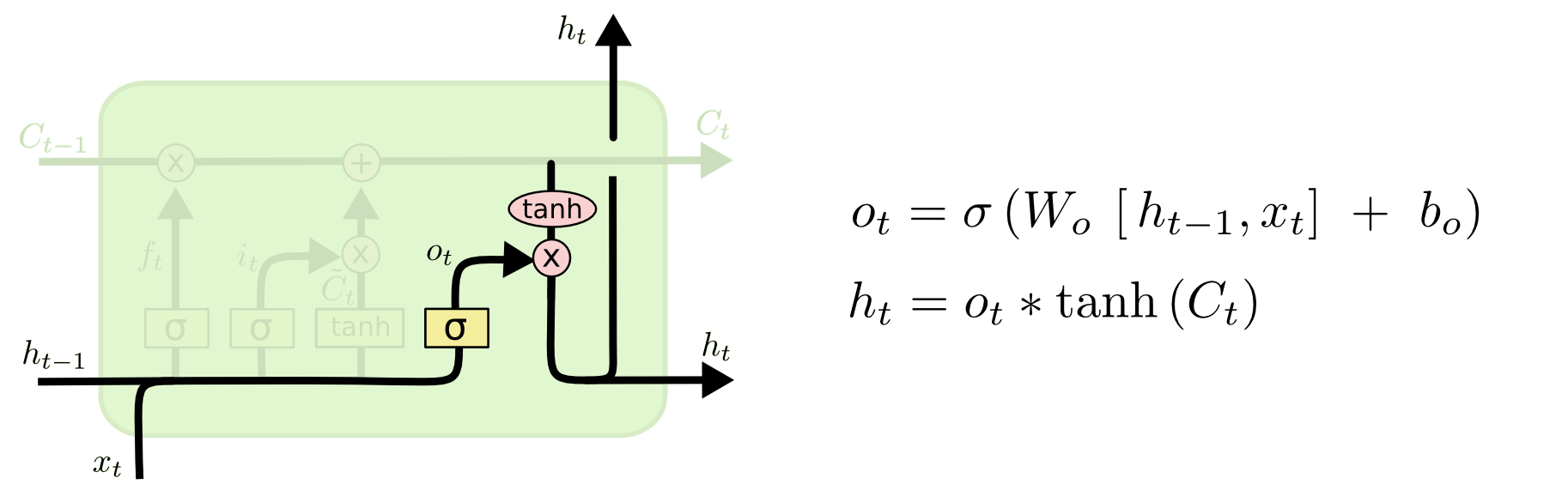
- Вот и все. Вы великолепны, а сеть переходит к следующему аналогичному блоку.
Фух, с базовой LSTM разобрались. Архитектура, хоть и выглядит сложной и перегруженной, работает на ура. Правда, у нее все же есть несколько проблем, из-за которых ее и победили в 2017 году трансформеры...
Проблемы архитектуры LSTM
- Ограниченная способность пересматривать решения о хранении информации. То есть, если сеть с помощью своих гейтов забыла какую-то информацию или, наоборот, запомнила ее как очень важную, то затем это решение сложно корректировать.
- Ограниченная способность хранить информацию. Память у LSTM скалярна, то есть информация должна быть сильно сжата, чтобы уместиться внутрь сети. Конечно, при таком сжатии мы теряем некоторые детали. Это хорошо заметно, в частности, когда сети нужно предсказать какой-то редко встречающийся токен.
- Как мы видели в предыдущем разделе, каждое последующее скрытое состояния сети зависит от предыдущего. Из-за такого механизма преобразования памяти (он называется memory mixing) невозможно распараллелить вычисления, поэтому LSTM считается плохо масштабируемой архитектурой.
К чему это все? А к тому, что в своей новой статье авторы придумали хаки, которые решают перечисленные проблемы, и оказалось, что xLSTM может стать полноправной альтернативой трансформерам в LLM. Но не будем забегать вперед, сначала разберемся с теорией.
sLSTM
Вообще говоря, xLSTM (Extended Long Short-Term Memory), которую предложили авторы, состоит из двух подсетей: sLSTM и mLSTM. В sLSTM ученые вводят две фичи: новый алгоритм memory mixing и экспоненциальные гейты.
Как мы уже разобрали, в ванильной LSTM гейты используются, чтобы сохранять в памяти сети только релевантную информацию. Для этого используется функция сигмоиды, которая сопоставляет каждой компоненте вектора информации число от 0 до 1, где 1 – это "запомнить полностью", а 0 - "забыть полностью". В xLSTM, чтобы решить проблему ограниченной способности сети пересматривать свои решения, в гейте забывания и гейте входного состояния на смену сигмоиде приходит экспонента. Для нормализации сети в блок также добавлено дополнительное состояние nt :
 Все изменения блока sLSTM по сравнению с ванильной LSTM на картинке выделены красным. Обратите внимание, что теперь в формировании скрытого состояния ht участвует не Сt, к которой применили гиперболический тангенс, а частное от деления состояния памяти ячейки Сt на состояние нормализации nt. Само состояние нормализации формируется как сумма:
Все изменения блока sLSTM по сравнению с ванильной LSTM на картинке выделены красным. Обратите внимание, что теперь в формировании скрытого состояния ht участвует не Сt, к которой применили гиперболический тангенс, а частное от деления состояния памяти ячейки Сt на состояние нормализации nt. Само состояние нормализации формируется как сумма:
 Экспонента может привести к появлению огромных значений весов сети, что влечет за собой проблему переполнения памяти. Так что помимо нормализации авторы также предлагают ввести состояние для стабилизации. По сути, это просто альтернативный способ вычисления выходов гейтов забывания и входного состояния:
Экспонента может привести к появлению огромных значений весов сети, что влечет за собой проблему переполнения памяти. Так что помимо нормализации авторы также предлагают ввести состояние для стабилизации. По сути, это просто альтернативный способ вычисления выходов гейтов забывания и входного состояния:
 Благодаря вычитанию максимумального из логарифмов выходов гейтов стабилизатор нивелирует риск взрыва весов и делает сеть более устойчивой.
Благодаря вычитанию максимумального из логарифмов выходов гейтов стабилизатор нивелирует риск взрыва весов и делает сеть более устойчивой.
Экспонента в гейтах, в совокупности с нормализацией и стабилизацией, не только повышает способность сети более гибко управлять своей памятью, но и открывает возможности к оптимизации. Так как теперь сеть умеет "пересматривать" решения, принятые ранее, вместо единой вытянутой цепочки блоков мы можем (наподобие того, как это происходит в трансформерах) добавить в сеть несколько голов, в каждой из которых будем отдельно осуществлять memory mixing.
mLSTM
C помощью mLSTM авторы решают проблему ограниченной способности ванильной LSTM хранить информацию. Здесь вместо скалярной ячейки памяти они используют матрицу. Эта матрица, в отличие от LSTM, будет обновляться вообще без использования предыдущих скрытых состояний сети. Для этого ученые снова позаимствовали идею из трансформеров и ввели в использование известный триплет (запрос qt, ключ kt, значение vt). Такое правило обновления называется правилом обновления ковариаций и в оригинале записывается так:
 Конечно же, внутри самой сети мы снова будем "взвешивать" каждую из компонент с помощью гейтов забывания и входного состояния:
Конечно же, внутри самой сети мы снова будем "взвешивать" каждую из компонент с помощью гейтов забывания и входного состояния:
 Сами гейты будут вычисляться также с помощью экспоненты, но без использования предыдущих скрытых состояний:
Сами гейты будут вычисляться также с помощью экспоненты, но без использования предыдущих скрытых состояний:
 Идея использования пар ключ-значения (kt-vt) заключается в следующем: так как каждая новая матрица состояния обновляется только за счет этих элементов, она также хранит в себе все прошлые пары k и v. Это позволяет нам на следующих шагах формировать скрытые состояния, просто извлекая необходимые нам знания из памяти с помощью запроса (query) qt. После извлечения остается только взвесить их с помощью гейта выходного состояния:
Идея использования пар ключ-значения (kt-vt) заключается в следующем: так как каждая новая матрица состояния обновляется только за счет этих элементов, она также хранит в себе все прошлые пары k и v. Это позволяет нам на следующих шагах формировать скрытые состояния, просто извлекая необходимые нам знания из памяти с помощью запроса (query) qt. После извлечения остается только взвесить их с помощью гейта выходного состояния:
 В формуле наверху обратите внимание на то, как нормализуется скрытое состояние. Здесь используется все то же состояние нормализации nt, которое мы обсуждали в части про sLSTM. Максимум, модуль и единица здесь использованы потому, что произведение nt на запрос может быть близко к нулю. В таких случаях лучше совсем обойтись без нормализации (поделить на единицу).
В формуле наверху обратите внимание на то, как нормализуется скрытое состояние. Здесь используется все то же состояние нормализации nt, которое мы обсуждали в части про sLSTM. Максимум, модуль и единица здесь использованы потому, что произведение nt на запрос может быть близко к нулю. В таких случаях лучше совсем обойтись без нормализации (поделить на единицу).
Осталось только понять, как вычисляются ключи, значения и запросы. К счастью, тут нет ничего особенного – это просто линейно преобразованные входные данные:
 Так как в mLSTM совсем нет memory mixing, то есть следующие скрытые состояния не зависят от предыдущих, вычисления можно запросто распараллелить. К тому же, хранение информации в виде матрицы значительно повышает способность архитектуры запоминать больше деталей.
Так как в mLSTM совсем нет memory mixing, то есть следующие скрытые состояния не зависят от предыдущих, вычисления можно запросто распараллелить. К тому же, хранение информации в виде матрицы значительно повышает способность архитектуры запоминать больше деталей.
xLSTM
Для того, чтобы из только что разобранных нами mLSTM и sLSTM собрать что-то единое (xLSTM), ученые дополнительно обернули каждую из структур в residual блоки.
Residual блоки (остаточные блоки) – это блоки, в которых входные данные X проходят через два или более слоев, а затем перед применением активации дополнительно суммируются с самим исходным входом X. Схематически это выглядит так: 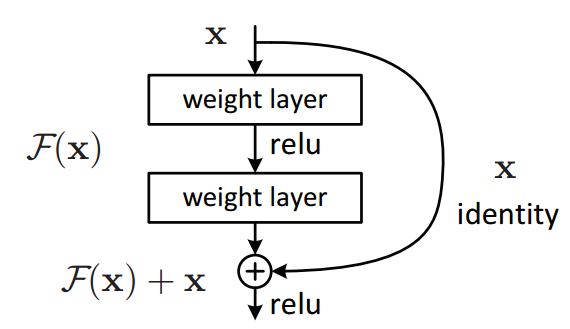 Для mLSTM и sLSTM в статье были предложены разные блоки:
Для mLSTM и sLSTM в статье были предложены разные блоки:
- Для sLSTM: входы X делятся на головы – на рисунке ниже их четыре. Перед этим входы опционально могут быть пропущены через несколько сверточных слоев. После деления в каждой из голов отрабатывает sLSTM. Выходы с голов затем объединяются с помощью GroupNorm, а потом проецируются в пространство большей размерности и обратно. Эта последняя часть названа up-projection и проделывается для того, что повысить качество histories separating. Это умение сети разделять "линии повествования": например, понимать, к какому из персонажей относится то или иное действие.
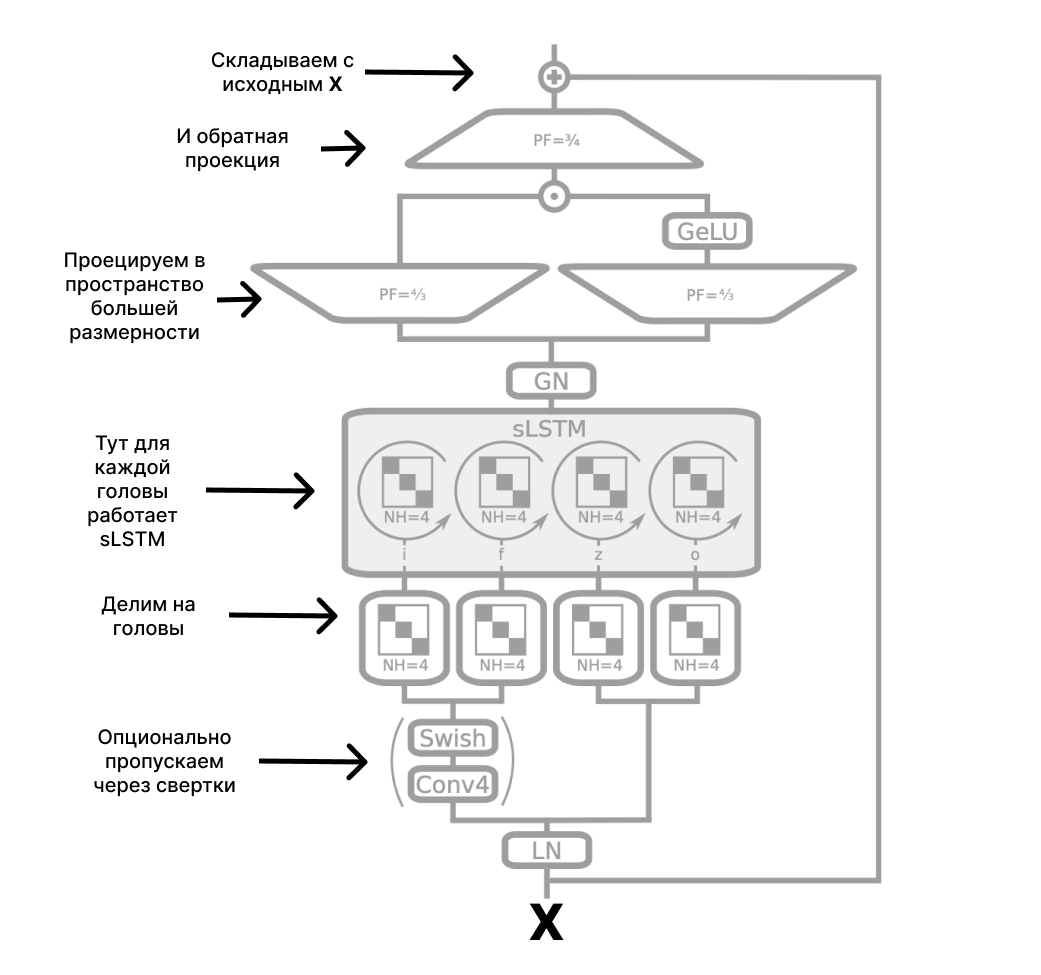
- Для mLSTM: все то же самое, что и в sLSTM, но в другом порядке. Отражаем входы в пространство большей размерности → делим на головы → пропускаем через mLSTM → объединяем по GroupNorm → проецируем обратно в родную размерность → складываем со входами, чтобы получится residual → готово!
Чтобы получилась xLSTM, такие residual блоки двух видов затем просто состыковываются друг с другом. Вот и все: такая замысловатая архитектура получилась у авторов.
Сравнение с трансформерами
Давайте по полочкам.
Обновление действительно вышло достойным. Авторы проверили, насколько ванильная LSTM отстает от xLSTM. Для этого они постепенно накручивали на LSTM новые фишки и оценивали, насколько это влияет на метрику. Только посмотрите, насколько падает перплексия после добавления остаточных блоков и замены гейтов на экспоненциальные:  В языковом моделировании xLSTM, обученная на 15B токенах, оказалась лучше всех остальных моделей (тут присутствуют трансформеры, SSM и RNN). Видно, что модель сопоставима с GPT-3 на 350М параметров.
В языковом моделировании xLSTM, обученная на 15B токенах, оказалась лучше всех остальных моделей (тут присутствуют трансформеры, SSM и RNN). Видно, что модель сопоставима с GPT-3 на 350М параметров.  Также xLSTM показывает хороший скейлинг, то есть может быть легко масштабируема.
Также xLSTM показывает хороший скейлинг, то есть может быть легко масштабируема.  Однако есть и проблемы. Во-первых, sLSTM нельзя распараллелить (хотя авторы приводят веские доводы в пользу того, что архитектуру вполне можно разогнать до приемлемых скоростей). Во-вторых, матрицы в mLSTM имеют высокую вычислительную сложность. В-третьих, более обширный контекст потенциально может перегрузить сетку, которая и без того требует очень тщательной оптимизации и подбора гиперпараметров.
Однако есть и проблемы. Во-первых, sLSTM нельзя распараллелить (хотя авторы приводят веские доводы в пользу того, что архитектуру вполне можно разогнать до приемлемых скоростей). Во-вторых, матрицы в mLSTM имеют высокую вычислительную сложность. В-третьих, более обширный контекст потенциально может перегрузить сетку, которая и без того требует очень тщательной оптимизации и подбора гиперпараметров.
xLSTM – это новые большие языковые модели?
Ответа на вопрос "заменят ли xLSTM трансформеры?" пока нет. Некоторые в ML сообществе настаивают на том, что это прорыв, другие в xLSTM не верят. Ясно одно: эта архитектура – новый виток Deep Learning и NLP, и она обладает большим потенциалом.
Исследование совсем свежее, оно вышло всего пару дней назад. Ресерчеры и инженеры еще не успели полностью погрузиться в xLSTM, тем более что официальный код авторы все еще не опубликовали. В общем, будем ждать на эту тему еще больше исследований и новостей!