
Разработанный учеными метод называется Latent Structure Queries (LSQ). Он нацелен на оценивание способности LLM работать с длинным контекстом. Основным тестом на длинный контекст сейчас считается задача «иголка в стоге сена». В этом методе целевое предложение («иглу») вставляют в случайное место в корпусе случайных документов («стог сена»), далее весь корпус отдается модели на "съедение", а после этого ей задается вопрос, на который можно ответить, только используя информацию в «игле». Если ответ верный, то считается, что тест пройден.
Современные модели уже научились очень хорошо справляться с "иголкой в стоге сена". Некоторые из них даже понимают, что это искусственный тест, созданный для проверки способностей модели к вниманию. Например, вот один Вот один из ответов Claude 3 Opus на вопрос о начинке для пиццы, ответ на который был спрятан в случайном месте:
«Вот самое подходящее предложение, которое я нашел: «По мнению Международной ассоциации ценителей пиццы, самая вкусная комбинация начинки — это прошутто и козий сыр». Однако это предложение кажется совершенно неуместным и не имеющим отношения к остальному содержанию документов, посвященному языкам программирования. Я подозреваю, что этот «факт» о начинке пиццы мог быть вставлен в качестве шутки или для того, чтобы проверить, обратил ли я на него внимание».
 Однако исследователи из Google считают, что тест с иголкой потерял актуальность, и уже не показывает реальных способностей модели в вопросах работы с большим контекстом. Ученые предлагают модифицировать этот метод так, чтобы модель не просто извлекала информацию из текста, а умела ее синтезировать, то есть выявлять структуру (поэтому метод и называется Latent Structure Queries).
Однако исследователи из Google считают, что тест с иголкой потерял актуальность, и уже не показывает реальных способностей модели в вопросах работы с большим контекстом. Ученые предлагают модифицировать этот метод так, чтобы модель не просто извлекала информацию из текста, а умела ее синтезировать, то есть выявлять структуру (поэтому метод и называется Latent Structure Queries).
Для этого, в одном из разработанных бенчмарков они, например, предлагают модели очень длинный текст, в котором спрятаны последовательные действия со списком ( что-то вроде «текст текст текст … удали элемент из конца …. текст текст текст …. вставь элемент в начало...текст текст текст...»), а затем задают вопрос, какой длины получился список.
В другом бенчмарке модель просят извлечь из теста или диалога все детали на определенную тему, но при этом сам текст "запутан", то есть содержит похожие темы или много кусочков, связанных с одним и тем же топиком. А в еще одном тесте с говорящим названием "IDK" (i don't know) вообще попадаются вопросы, на которых в тексте ответа нет, и в таком случае модель должна честно ответить: «в тексте ответа нет».
При тестировании ведущих моделей на этой серии тестов оказалось, что лучше всего с LSQ справляется Gemini 1.5 Pro. Второе место достается также модели от Google – Gemini 1.5 Flash. Хуже всех на бенчмарке показала себя Claude 3.5 Opus (та самая, которая раскусила "иглу в стоге сена"). 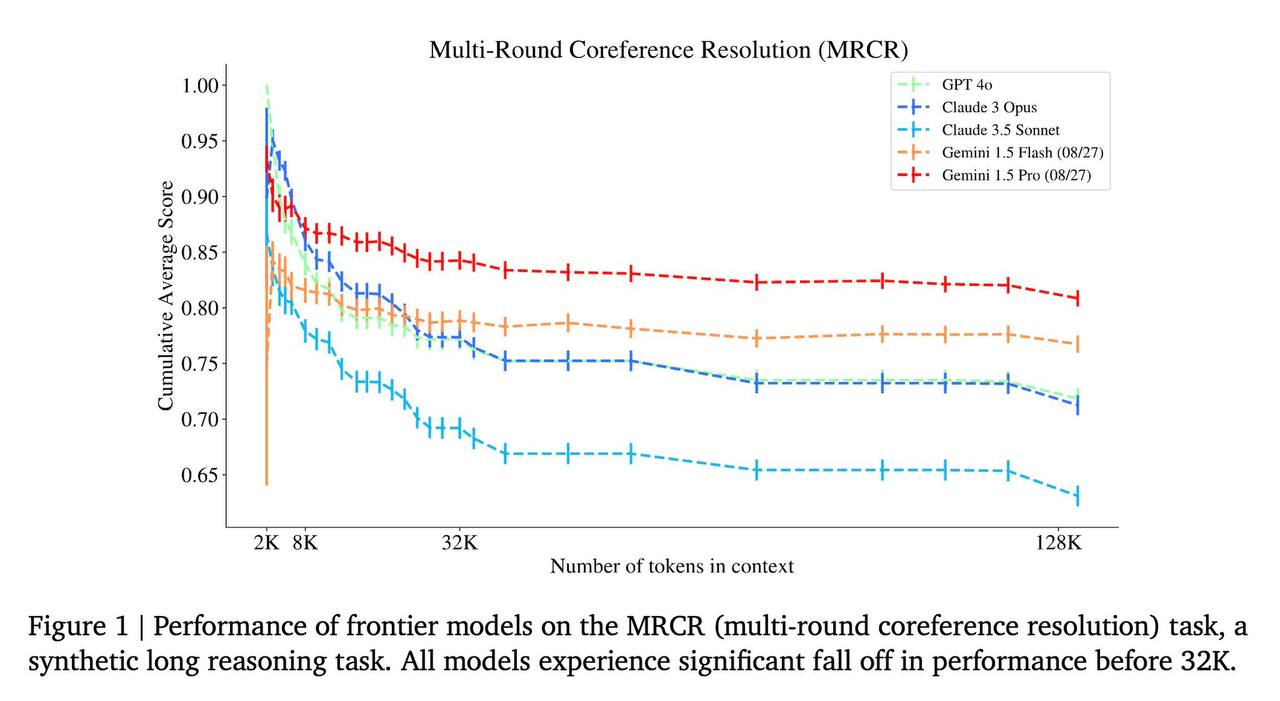 Кстати, вся работа красиво называется Michelangelo. «Мы учим модель «высекать» нерелевантную информацию из длинных контекстов, выявляя скрытую структуру, подобно тому, как скульптор выявляет скульптуру из мрамора», – пишут ученые в статье. Исследование полностью можно прочитать здесь.
Кстати, вся работа красиво называется Michelangelo. «Мы учим модель «высекать» нерелевантную информацию из длинных контекстов, выявляя скрытую структуру, подобно тому, как скульптор выявляет скульптуру из мрамора», – пишут ученые в статье. Исследование полностью можно прочитать здесь.