
Впервые метода EAGLE (Extrapolation Algorithm for Greater Language-model Efficiency) команда исследователей канадского Университет Ватерлоо представила в конце 2023 года. Он использует экстраполирование векторов контекстных признаков второго верхнего слоя языковых моделей, что положительно сказывается на эффективности генерации ответов. В результате разработчики могут запускать требовательные модели на более доступном железе.
Обновлённый метод EAGLE-2 позволяет генерировать ответы языковых моделей на двух видеокартах RTX 3060 быстрее, чем на более продвинутой A100. При этом сетап из двух RTX 3060 обойдётся 600 долларов, а за профессиональный видеоускоритель A100 придётся отдать не менее 10 тыс. долларов. Если сравнивать по скорости генерации, то EAGLE:
- в четыре раза быстрее обычного запуска LLM (13B);
- в два раза быстрее Lookahead (13B);
- в 1,6 раза быстрее Medusa (13B).
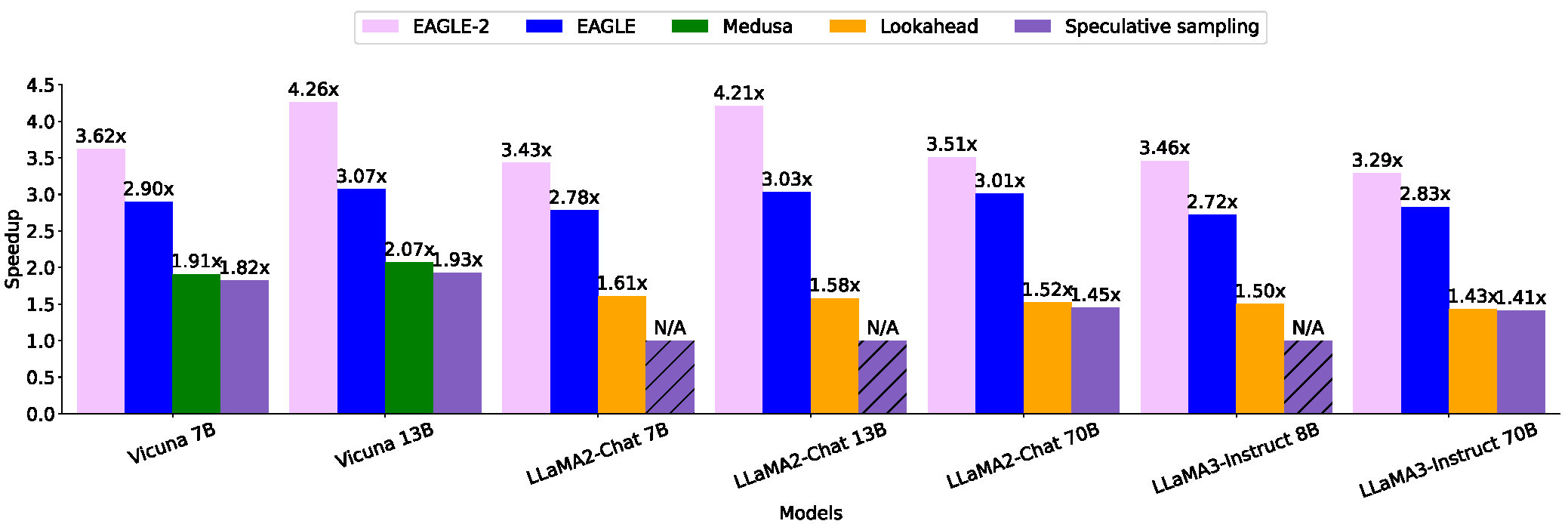
Метод совместим с языковыми моделями LLaMA2-Chat, LLaMA3-Instruct, Mixtral и Vicuna. На GitHub исследователи опубликовали код метода и инструкции по локальному запуску. На платформе Hugging Face доступы веса.
Инференс EAGLE выглядит следующим образом:
from eagle.model.ea_model import EaModel
from fastchat.model import get_conversation_template
model = EaModel.from_pretrained(
base_model_path=base_model_path,
ea_model_path=EAGLE_model_path,
torch_dtype=torch.float16,
low_cpu_mem_usage=True,
device_map="auto",
total_token=-1
)
model.eval()
your_message="Hello"
conv = get_conversation_template("vicuna")
conv.append_message(conv.roles[0], your_message)
conv.append_message(conv.roles[1], None)
prompt = conv.get_prompt()
input_ids=model.tokenizer([prompt]).input_ids
input_ids = torch.as_tensor(input_ids).cuda()
output_ids=model.eagenerate(input_ids,temperature=0.5,max_new_tokens=512)
output=model.tokenizer.decode(output_ids[0])