
Если вы когда-либо работали с рекомендательными системами, то знаете, что все необходимые и самые часто используемые инструменты разбросаны по разным библиотекам. Более того, каждая из таких библиотек имеет много уникальных особенностей, к которым нужно приноровиться (например, разные форматы данных на вход).
Выходит, что чтобы просто протестировать на своей задаче базовый пул подходов, нужно немало помучиться. Получается довольно грустно.
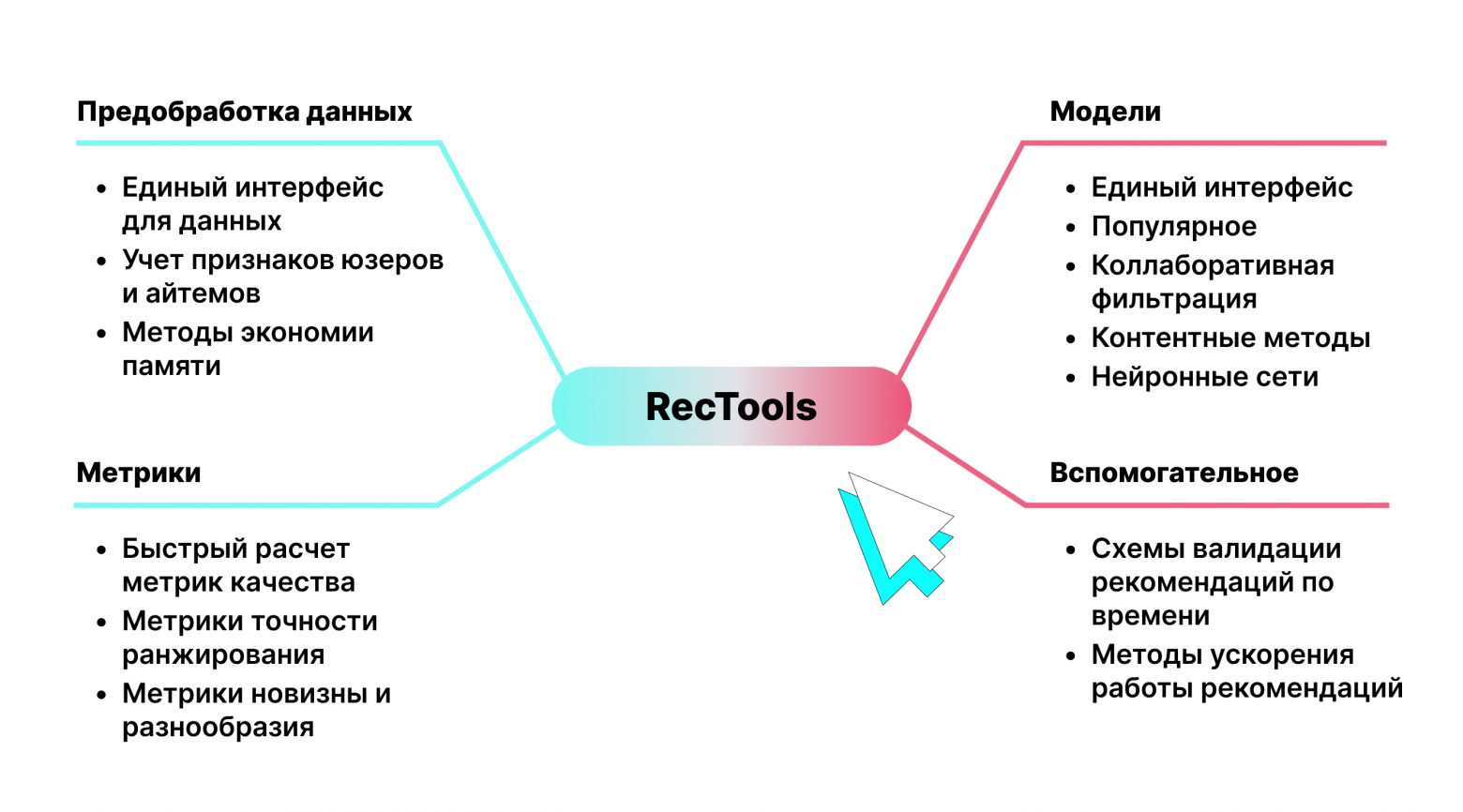
К такому же выводу, видимо, пришли ребята из МТС – и выкатили в опенсурс RecTools. Это библиотека, где собраны самые часто используемые модели для рекомендательных систем. Также с её помощью можно максимально просто и быстро оценивать необходимые метрики.
Сегодня мы решили разобраться, что RecTools умеет, и как с этим работать.
Кстати, кроме сайта у нас есть телеграм-канал: https://t.me/data_secrets. Туда мы публикуем самые свежие новости, мемы и наши полезные ML-находки. Подписывайтесь, чтобы не пропустить!
Также нам помогли усовершенствовать эту статью сами разработчики RecTools, за что мы выражаем им большую благодарность :)
Установка
Тут никаких особых усилий не требуется, устанавливаем через привычный менеджер:
pip install rectoolsПомимо этого, можно установить дополнительные расширения:
- LightFM: wrapper для модели LightFM
- torch: модели на основе нейронных сетей
- nmslib: fast ANN рекомендации
Как установить расширение:
pip install rectools[extension-name]Если хотите установить все расширения сразу:
pip install rectools[all]Как подавать данные
Мы уже упоминали, что разные библиотеки зачастую требуют разные форматы данных на вход. RecTools решает и эту проблему. Внутри реализован контейнер, который агрегирует всё, что есть по задаче. Так что обработали один раз – и подаем во все модели одинаково.
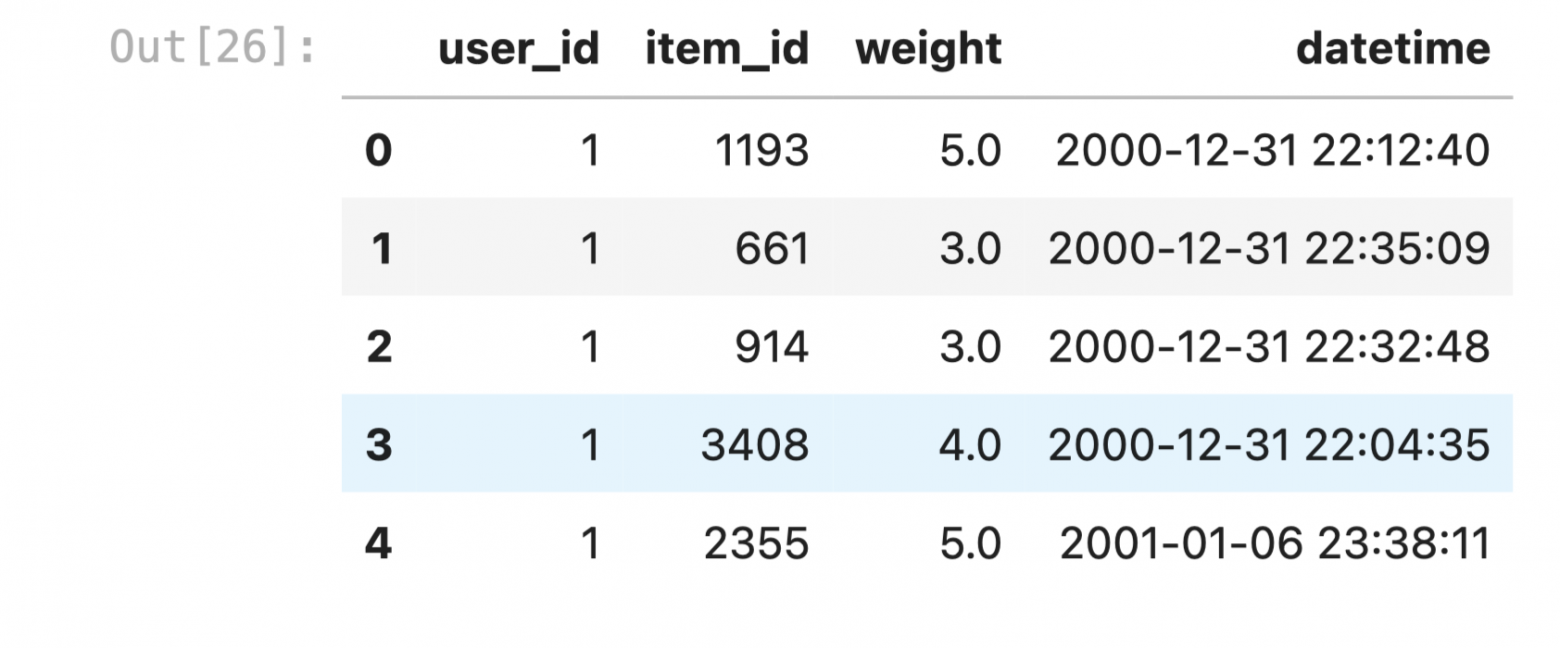 По факту от пользователя требуется обычная таблица, где каждая строка отражает одно взаимодействие: в первом столбце id юзера, во втором — айтема, а в третьем — скор взаимодействия (например, купил/ не купил). Если есть данные по времени, их тоже можно добавить.
По факту от пользователя требуется обычная таблица, где каждая строка отражает одно взаимодействие: в первом столбце id юзера, во втором — айтема, а в третьем — скор взаимодействия (например, купил/ не купил). Если есть данные по времени, их тоже можно добавить.
Из особенностей: имена столбцов фиксированы. Поэтому колонки нужно будет переименовать с помощью класса Columns. Затем остается просто обернуть все в Dataset и готово:
from rectools import Columns
ratings = pd.read_csv(
"ml-1m/ratings.dat",
sep="::",
engine="python",
header=None,
names=[Columns.User, Columns.Item, Columns.Weight, Columns.Datetime],
)
# Prepare a dataset to build a model
dataset = Dataset.construct(ratings)
Модели библиотеки
В библиотеке реализовано единое API для всех широко известных моделей: Implicit ItemKNN, ALS, SVD, Lightfm, DSSM и пр. То есть вся разнообразная механика инструментов оказывается спрятанной под капотом, а сами модели работают из коробки – с помощью единых методов fit – recommend.
Модель "популярное"
Это база. Алгоритм работает просто: на основе данных делает выводы о том, с какими продуктами пользователи чаще всего взаимодействуют (смотрят или покупают) и рекомендует их всем. Конечно, особой положительной репутацией метод не обладает, но его можно улучшить с помощью простого трюка. Нужно всего лишь рекомендовать с некоторой рандомизацией. Например, каждый раз брать 10 случайных айтемов из топ-100 самых популярных. Называется reranking diversity.
Может показаться, что и это слишком наивно. Но на практике такой подход показывает устойчивый статзначимый эффект и получается настолько сильным, что часто выигрывает на AB многие популярные модели, в том числе ALS и LightFM. К тому же, такие рекомендации обходятся бизнесу очень дешево.
Короче, если ищете, с чего начать – начните с популярного. В RecTools реализовать модельку можно вот так
from rectools.models import PopularModel
# Fit model and generate recommendations for all users
model = PopularModel()
model.fit(dataset)
recos = model.recommend(
users=ratings[Columns.User].unique(),
dataset=dataset,
k=10,
filter_viewed=True,
)
Матричные разложения
Матричные разложения – это такие методы коллаборативной фильтрации. Вкратце: это прогнозирования действий пользователя на основе действий других пользователей с похожим поведением. Представим, что у нас есть некоторая матрица user-item. Строки — пользователи, столбцы — айтемы. На пересечении пользователя и айтема стоит число, отражающее взаимодействие.
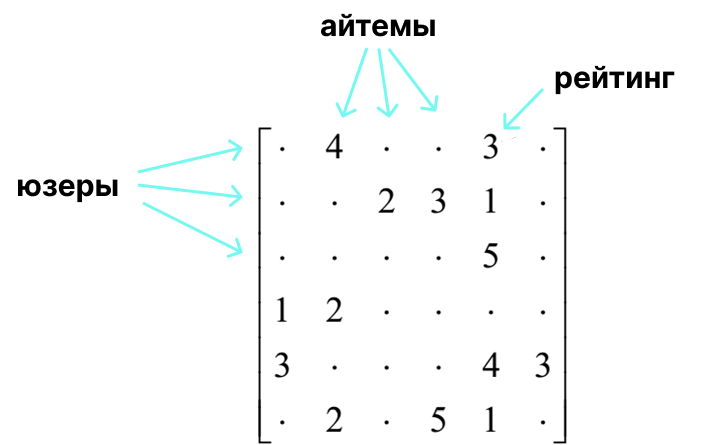 На основе такой матрицы мы можем описать поведение пользователей и характеристики айтемов. Для этого используются методы спектрального разложения. Один из них – алгебраическое разложение матриц, SVD (singular value decomposition). В основе — разложение исходной матрицы в произведение 3 других:
На основе такой матрицы мы можем описать поведение пользователей и характеристики айтемов. Для этого используются методы спектрального разложения. Один из них – алгебраическое разложение матриц, SVD (singular value decomposition). В основе — разложение исходной матрицы в произведение 3 других:
U и S – матрицы представлений пользователей и айтемов соответственно. Используя эти матрицы, далее мы можем получать рекомендации. В RecTools этот инструмент можно использовать с помощью класса PureSVDModel:
from rectools.models import PureSVDModel
# Fit model and generate recommendations for all users
model = PureSVDModel()
model.fit(dataset)
recos = model.recommend(
users=ratings[Columns.User].unique(),
dataset=dataset,
k=10,
filter_viewed=True,
)
Алгоритм достаточно прозрачный, но у него есть недостатки. Во-первых, он не интерпретируемый, так как предсказания делаются на основе скрытых представлений. Во-вторых, вычисление таких разложений весьма трудоемко. В-третьих, SVD решает задачу разложения исходной матрицы напрямую, пытаясь восстановить все пропущенные значения нулями. И является идеальным решением такой задачи с математической точки зрения. Но по факту пропущенные значения в матрице взаимодействий - это необязательно нули (юзеры могли просто не успеть про-взаимодействовать с релевантными айтемами).
Поэтому на практике чаще используется ALS (alternating least squares) – это эвристический приближенный алгоритм для разложения матриц. На выходе снова получаем эмбеддинги юзеров и айтемов, с помощью которых делаем рекомендации.
Использование этого алгоритма из волшебной коробки RecTools немного отличается от предыдущих алгоритмов. Так как эта имплементация – просто обертка для модели из implicit, на вход объекту класса нужно подать Base model (подробнее тут), внутри которой уже можно указать необходимые параметры, вот так:
from rectools.models import ImplicitALSWrapperModel
from implicit.als import AlternatingLeastSquares
model = ImplicitALSWrapperModel(
AlternatingLeastSquares(
factors=64,
regularization=0.01,
alpha=1,
random_state=2023,
use_gpu=False,
iterations=15))
Обучение и получение же самих рекомендаций не меняется – для этого, как и прежде, можно использовать методы fit и recommend.
Implicit KNN
Помимо обертки для модели ALS из библиотеки implicit, в RecTools также представлен wrapper для модели item-to-item KNN recommender оттуда же. Суть такова: ищем в матрице по методу ближайших соседей айтемы, максимально похожие на айтемы из истории взаимодействий юзера, и именно их ему рекомендуем.
from rectools.models import ImplicitItemKNNWrapperModel
from implicit.nearest_neighbours import TFIDFRecommender
model = ImplicitItemKNNWrapperModel(
model=TFIDFRecommender(K=5)
)
model.fit(dataset)
Как видите, внутрь также нужно подать базовую модель. В коде выше это TFIDFRecommender, но на самом деле на этот раз у нас есть на эту роль несколько кандидатов, в зависимости от расстояния, которым будет измеряться сходство в алгоритме ближайших соседей: CosineRecommender, TFIDFRecommender или BM25Recommender. Подробнее про разницу между ними можно почитать здесь.
LightFM
Это модель гибридной матричной факторизация, которая к тому же хорошо работает для случая холодного старта: это когда нам попадаются товары или юзеры, которые не представлены в матрице взаимодействия.
Воспользоваться моделью по-прежнему просто, только не забудьте установить библиотеку lightfm с помощью pip install lightfm и соответствующе расширение для RecTools.
from rectools.models import LightFMWrapperModel
from lightfm import LightFM
model = LightFMWrapperModel(
# внутри модели указываем параметр no_components
# это размезность эмбеддингов, которые выучит модель
model=LightFM(no_components = 30)
)
model.fit(dataset)
recos = model.recommend(
users=ratings[Columns.User].unique(),
dataset=dataset,
k=10,
filter_viewed=True,
)
Подробнее про алгоритм можно прочитать в оригинальной статье 2015 года.
DSSM
Мы уже поняли, что если пользователи и айтемы описываются векторами одного пространства, то релевантность айтема пользователю описывается близостью их векторов. Получается, поиск топ-к самых релевантных айтемов сводится к поиску k ближайших соседей.
То есть, нам нужна модель, которая моделирует релевантность с помощью скалярного произведения эмбеддингов. Одна из таких моделей – DSSM – была придумана в 2013 году исследователями из Microsoft. Идея этой простой нейросети такая: давайте сделаем две "башни" с полносвязными слоями и нелинейностями: одна башня будет для юзеров, вторая для айтемов.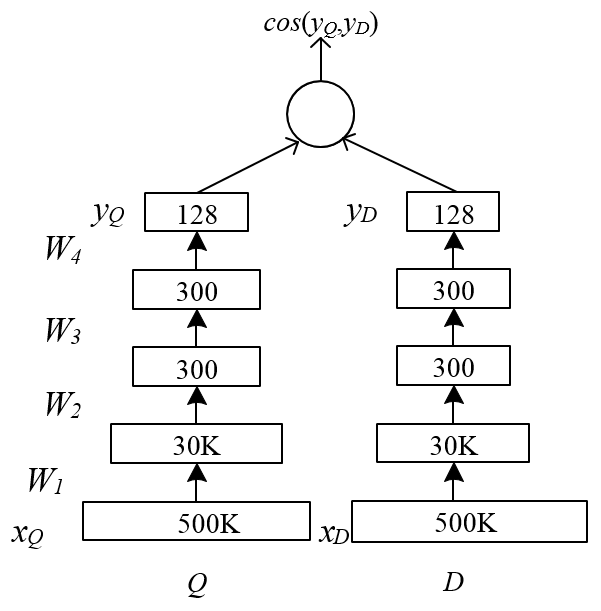 На выходе каждая из этих башен будет выдавать эмбеддинги юзера и айтема, а косинус угла между этими векторами будет моделировать релевантность айтема юзеру.
На выходе каждая из этих башен будет выдавать эмбеддинги юзера и айтема, а косинус угла между этими векторами будет моделировать релевантность айтема юзеру.
В RecTools есть имплементация и этого алгоритма. Авторы реализовали его сами с помощью фреймворка PyTorch Lightning. Чтобы воспользоваться моделью, не забудьте установить нужное разрешение.
from rectools.models import DSSMModel
model = DSSMModel(dataset,
max_epochs = 10,
batch_size = 64
)
model.fit(dataset)
Добавление атрибутов в модели
Ну, а что, если мы хотим учитывать не только взаимодействия пользователей и объектов, но и какие-то их отличительные признаки – атрибуты? Понятно ведь, что часто одинаковые товары нравятся людям одного возраста, пола, профессии и пр. А для объектов атрибутами могут стать производитель, цена и многое другое, в зависимости от того, что именно мы рекомендуем.
В RecTools есть функционал, который позволяет добавлять фичи пользователей и айтемов во многие перечисленные в предыдущем разделе модели (iALS, LightFM, DSSM, PopularInCategory).
Для начала нужно приготовить данные о юзерах и/или айтемах специальным образом. Во-первых, все признаки нужно "вытянуть" в одну колонку value, пометив каждое значение названием фичи, к которой оно относится.
# загружаем данные
users = pd.read_csv(
"ml-1m/users.dat",
sep="::",
engine="python",
header=None,
names=[Columns.User, "sex", "age", "occupation"],
)
# отбираем только тех юзеров, которые есть в таблице взаимодействий
users = users.loc[users["user_id"].isin(ratings["user_id"])].copy()
# вытягиваем фичи в одну колонку и метим
user_features_frames = []
for feature in ["sex", "age", "occupation"]:
feature_frame = users.reindex(columns=["user_id", feature])
feature_frame.columns = ["id", "value"]
feature_frame["feature"] = feature
user_features_frames.append(feature_frame)
user_features = pd.concat(user_features_frames)
 После остается заново обернуть основной датасет в специальный класс, при этом указав значения аргументов, которые отвечают за фичи. Если у вас представлены только числовые фичи, то можно поставить
После остается заново обернуть основной датасет в специальный класс, при этом указав значения аргументов, которые отвечают за фичи. Если у вас представлены только числовые фичи, то можно поставить make_dense_user_features=True. Иначе стоит придать этому аргументу значение False – это будет соответствовать sparse-формату представления данных.
sparse_features_dataset = Dataset.construct(
ratings,
# датасет фич
user_features_df=user_features,
# к этим фичам будет применен One Hot Encoding
cat_user_features=["sex", "age"],
# для `sparse` формата
make_dense_user_features=False
)
После этого мы снова готовы скармливать датасет моделям (здесь никаких изменений в коде нет). Например:
model = ImplicitALSWrapperModel(AlternatingLeastSquares(10, num_threads=32))
model.fit(sparse_features_dataset)
Метрики
Разработчики также добавили в RecTools все основные метрики, которые могут пригодится при оценке ваших рекомендательных моделей. При этом они не только сохраняют единый интерфейс, но еще и хорошо оптимизированы:
"Мы решили использовать подход, который позволяет считать метрики на основе табличных данных. Это похоже на Single Instruction Multiple Data. То есть это инструкции в самом процессоре, которые могут применять одну и ту же простую операцию (типа сложения и умножения) к нескольким блокам данных. Это занимает меньше кода, сохраняет интерпретируемость, так ещё и работает в сотни раз быстрее."
Вот так вы можете посчитать, например, классическую ndcg для ваших рекомендаций:
ndcg = NDCG(k=10, log_base=3)
print("NDCG: ", ndcg.calc(reco=recos, interactions=df_test))
# 0.068
Помимо этой метрики, в библиотеке также представлены: Accuracy, F1Beta, IntraListDiversity, MAP, MCC, MRR, MeanInvUserFreq, Precision, Recall, Serendipity.
Заключение
RecTools – отличная библиотека, которая собрала в себе все самые необходимые модели, метрики и инструменты для построения рекомендательных систем. Туда также внедрены методы ускорения работы рекомендаций, многие модели поддерживают GPU.
Библиотека постоянно дорабатывается и оптимизируется. Например на последних бенчмарках зафиксировано ускорение инференса для LightFM в 10-25 раз, а также прирост качества для iALS с фичами на 50%.
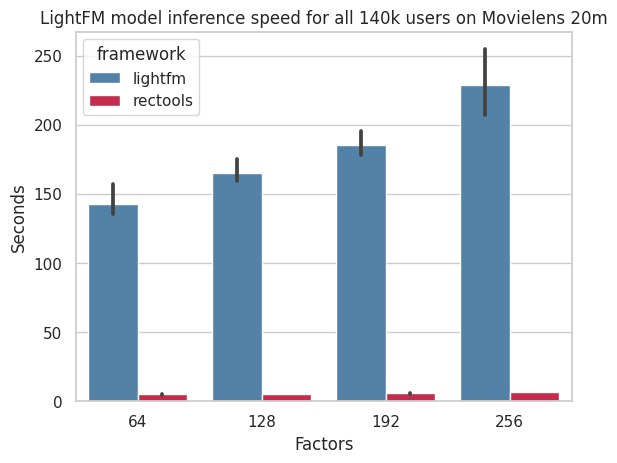
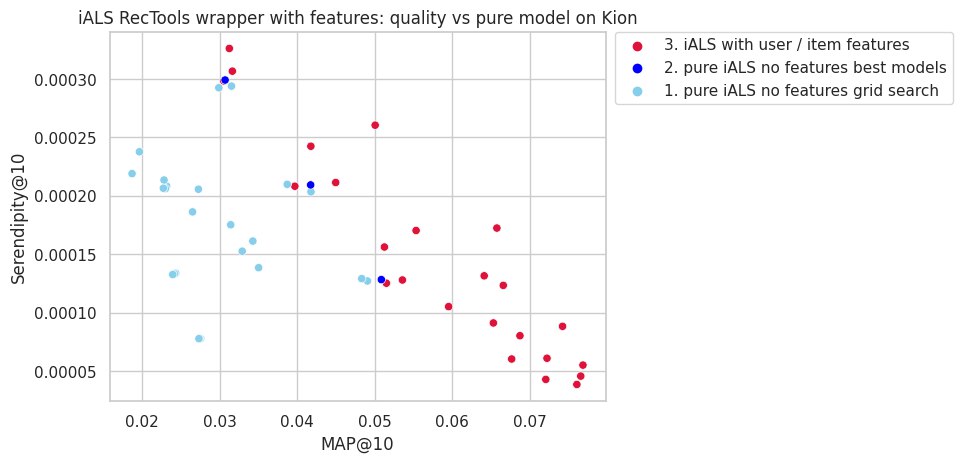 В общем, не поскупитесь – поставьте ребятам звездочку на GitHub :)
В общем, не поскупитесь – поставьте ребятам звездочку на GitHub :)
Дополнительные материалы
Если хотите глубже погрузиться в тему, вам будут полезны следующие ресурсы:
- Документация RecTools
- RecTools на GitHub(обязательно загляните в туториалы – там много полезного)
- Документация LightFM
- Доклад Виктора Кантора, в котором он рассказывает про RecTools и рекомендации в МТС
- Implicit на GitHub
- Документация Implicit