
YOLO расшифровывается как You Only Look Once. Это широко известная архитектура компьютерного зрения, которая знаменита в том числе своим огромным количеством версий: первая из них вышла в 2016 году и решала только задачу детекции объектов на изображении, а последняя – одиннадцатая – появилась в сентябре этого года и уже представляет из себя целую фундаментальную модель, которую можно использовать для классификации, трекинга объектов на видео, задач pose estimation и тд. Все это – в реальном времени.
Да, скорость – это именно то, что выделило YOLO среди других моделей восемь лет назад. До нее в мире CV существовали и другие архитектуры детекции. Например, в 2015 году лучшей считалась Faster R-CNN. Но, несмотря на слово "faster" в названии, эта моделька все еще тормизила на онлайн-тестах из-за своей нагроможденной структуры. Поэтому когда ученые из Вашингтона предложили YOLO, которая рвала конкурентов по времени и при этом показывала хорошие метрики, – это, фактически, перевернуло СV. За следующие 8 лет своего существования YOLO стала своеобразным трансформером во вселенной компьютерного зрения: ее любят и используют повсеместно.
Эта статья – полноценная техно-история YOLO. Мы расскажем, что представляет из себя задача детекции, как работала самая первая YOLO и как ее дорабатывали во всех последующих версиях. Поехали!
Задача детекции – как ее решать?
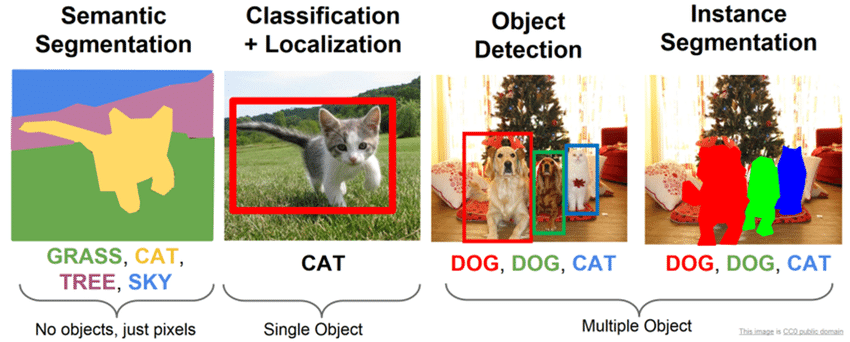
Детекция – это один из подвидов проблемы нахождения объектов на изображении. Почему "подвидов"? Потому что несмотря на то, что найти объект на изображении – задача вроде понятная, если вдуматься, звучит она достаточно размыто. Что значит найти? Просто определить, есть ли определенный объект на фото? Найти все объекты на фото? А найти – это просто перечислить или еще и обозначить прямо на изображении? А как обозначить?... Оказывается, в зависимости от ответов на эти вопросы и задача формально называется по-разному:
- Если нужно определить наличие или отсутствие объекта определённого домена на изображении – это классификация (classification)
- Если нужно выполнить классификацию, и к тому же определить рамку, ограничивающую местоположение экземпляра одиночного объекта на картинке, – это классификация с локализацией (classification and localization)
- Если нужно для каждого пикселя на картинке определить его принадлежность к определённой категории – это семантическая сегментация (semantic segmentation)
- Если нужно выполнить сегментацию, но при этом дифференцировать только объекты определенной сущности – это сегментация экземпляров (instance segmentation)
- Детекцией (object detection) же традиционно называют задачу, в которой необходимо выделить несколько объектов на изображении посредством нахождения координат их ограничивающих рамок и классификации этих ограничивающих рамок из множества заранее известных классов. При этом, в отличие от задачи классификации с локализацией, количество объектов на изображении заранее неизвестно.
 Рамки, в которые нужно заключать объекты, называются bounding boxes или просто b-boxes. Б-боксы традиционно имеют прямоугольную форму и располагаются так, чтобы стороны прямоугольника были параллельны рамкам изображения. Так же интуитивно понятно, что рамка должна быть "минимальной", то есть захватывать объект полностью так, чтобы при этом иметь минимальную площадь. То, как мы задаем б-бокс – зависит уже от нашей архитектуры, но обычно выбирают один из двух вариантов: координаты центра (
Рамки, в которые нужно заключать объекты, называются bounding boxes или просто b-boxes. Б-боксы традиционно имеют прямоугольную форму и располагаются так, чтобы стороны прямоугольника были параллельны рамкам изображения. Так же интуитивно понятно, что рамка должна быть "минимальной", то есть захватывать объект полностью так, чтобы при этом иметь минимальную площадь. То, как мы задаем б-бокс – зависит уже от нашей архитектуры, но обычно выбирают один из двух вариантов: координаты центра (x0, y0) + ширина(l) и высота(h), либо координаты верхнего левого пикселя (x1,y1) + координаты нижнего правого (x2,y2).
Обратите внимание, что в задаче детекции модель должна уметь решать сразу две проблемы: поиск оптимальных б-боксов и классификация. Тут самый наивный подход, приходящий в голову, – перебрать всевозможные б-боксы и прогнать каждый из них через классификатор на основе сверток. Но всем известно, что почти любой полный перебор – это невозможно долгий и неэффективный процесс. Поэтому в реальных архитектурах его немного докручивают. Например, есть группа методов, называемых двухэтапными, которые на первом шаге отбирают только некоторые б-боксы, с высокой вероятностью содержащие объект, а на втором такие избранные рамки скармливают классификатору. К таким методам относится R-CNN и его потомки Fast R-CNN и Faster R-CNN.
YOLO же стала первым представителем другой группы методов – одноэтапных алгоритмов, в которых отдельная модель для отбора регионов вообще не используется. Вместо этого YOLO представляет из себя единую сеть, которая сразу предсказывает координаты некоторого количества б-боксов вместе с их характеристиками, такими, как вероятность класса.
YOLOv1
Итак, в основе YOLOv1 лежит следующая архитектура:
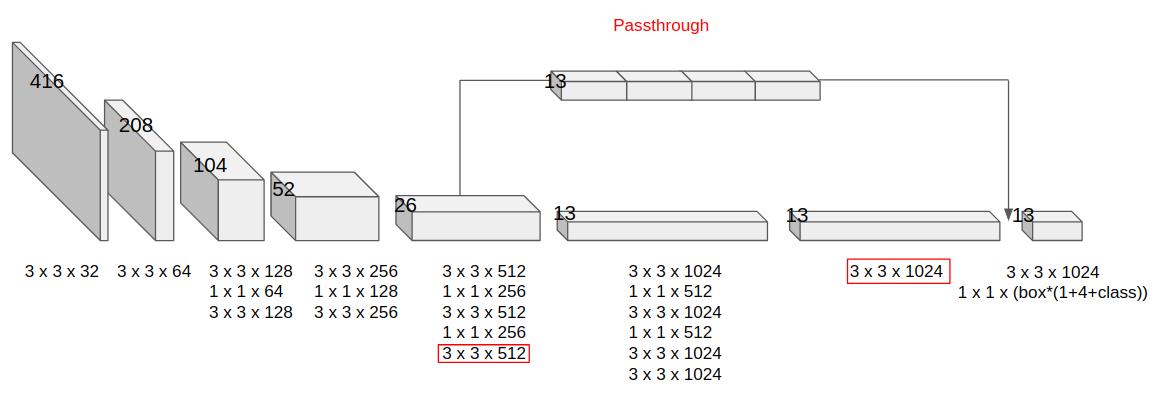
 Это немного видоизмененный GoogLeNet: в оригинальной СNN 22 сверточных слоя, но создатели YOLO добавили еще два + полносвязные слои в конце. На вход этой сети подается изображение 448x448 (да, если подать изображение другого размера, то оно просто обрежется и/или отправится на съедение функции resize), которое предварительно было разделено на одинаковые квадратные ячейки размера 64x64 таким образом, что получается как бы таблица 7х7 (нет, 7x7 – не волшебная константа, вы можете использовать и другой размер ячеек, но как это повлияет на сеть – никто особо не исследовал). Ячейки нам нужны для того, чтобы все операции далее происходили как бы на "клеточном" уровне. В этом заключено главное новшество YOLO: ее создатели смогли сформулировать и решать задачу детекции как задачу регрессии.
Это немного видоизмененный GoogLeNet: в оригинальной СNN 22 сверточных слоя, но создатели YOLO добавили еще два + полносвязные слои в конце. На вход этой сети подается изображение 448x448 (да, если подать изображение другого размера, то оно просто обрежется и/или отправится на съедение функции resize), которое предварительно было разделено на одинаковые квадратные ячейки размера 64x64 таким образом, что получается как бы таблица 7х7 (нет, 7x7 – не волшебная константа, вы можете использовать и другой размер ячеек, но как это повлияет на сеть – никто особо не исследовал). Ячейки нам нужны для того, чтобы все операции далее происходили как бы на "клеточном" уровне. В этом заключено главное новшество YOLO: ее создатели смогли сформулировать и решать задачу детекции как задачу регрессии.
Если вы обратите внимание на последний слой схемы, то заметите, что выходной тензор сети имеет размер 7х7х30. То есть для каждой из 7х7 ячеек нашего изображения модель предсказывает вектор из 30 чисел. Внутри этого вектора и скрывается описание б-боксов и меток классов. Если точнее, то первые 10 значений отвечают за координаты двух б-боксов-кандидатов: координаты центра + ширина + высота + confidence score, то есть уверенность модели в том, что внутри б-бокса находится центр объекта. Оставшиеся 20 значений вектора ответственны за метки классов, то есть оценку вероятности того, что объект определенного класса присутствует в ячейке. Почему 20? Потому что столько было классов в оригинальном датасете.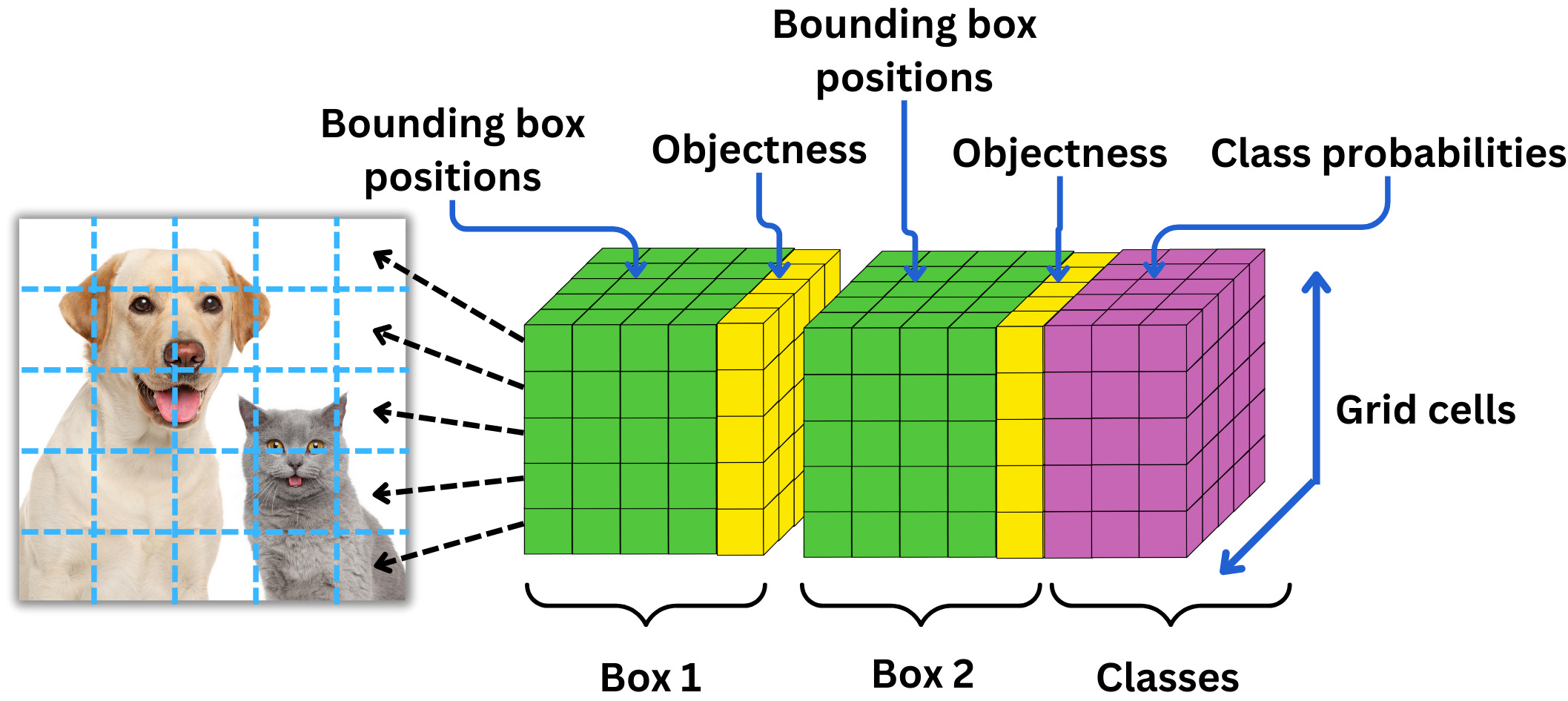 С архитектурой – все. Теперь посмотрим, как она обучается. Надо упомянуть, что перед тем, как обучать модель полностью, исследователи сначала дообучали 4 слоя в конце на размере изображений 448х448 (в отличие от первых 20 классификационных слоев, обученных на 224х224 ImageNet). Но вернемся к основному лоссу YOLO. Он представляет из себя сложную склейку классических лоссов классификации и детекции и выглядит довольно устрашающе:
С архитектурой – все. Теперь посмотрим, как она обучается. Надо упомянуть, что перед тем, как обучать модель полностью, исследователи сначала дообучали 4 слоя в конце на размере изображений 448х448 (в отличие от первых 20 классификационных слоев, обученных на 224х224 ImageNet). Но вернемся к основному лоссу YOLO. Он представляет из себя сложную склейку классических лоссов классификации и детекции и выглядит довольно устрашающе:
 Будем разбираться по частям. С первой частью, которая помечена как regression loss, все довольно просто. Это ошибка в предсказании координат центра (
Будем разбираться по частям. С первой частью, которая помечена как regression loss, все довольно просто. Это ошибка в предсказании координат центра (x,y), высоты (h) и ширины (w) б-боксов. Индекс i отвечает за объекты, индекс j – за боксы. Жирная красивая единица здесь – это индикаторная функция, которая позволяет учитывать в выражении только ячейки, в которых есть объекты, и только вклад рассматриваемого б-бокса j (если это все тот же объект i, но бокс другой, выражение обнулится, чтобы дважды не учитывать одну и ту же ошибку). Что касается корней, которые применяются к высоте и ширине б-боксов, то это просто мера масштабирования, необходимая для того, чтобы больше штрафовать маленькие б-боксы за несоответствие реальной разметке.
С последней частью – classification loss – все тоже понятно. Это классический квадратичный лосс, в котором мы считаем ошибки на тех самых двадцати метках классов. При этом индикаторная функция здесь снова гарантирует, что будут учтены только те ячейки, в которых действительно есть объект. Ячейки без объектов мы, конечно, тоже учитываем далее, но для лосса важно сохранение баланса, и так как в большинстве ячеек объектов вообще не будет, то клеткам, содержащим что-либо, необходимо отдавать больший вес.
Наконец, Confidence loss. Это та часть функции потерь, которая отвечает за оценки "уверенности" модели в том, что внутри б-бокса находится центр объекта (они обозначены желтым на предыдущей схеме). При этом это не просто вероятность. Это предсказанное значение функции IoU, то есть Intersection over Union. Эта одна из определяющих метрик компьютерного зрения, и проще всего ее понять, просто посмотрев на картинку: 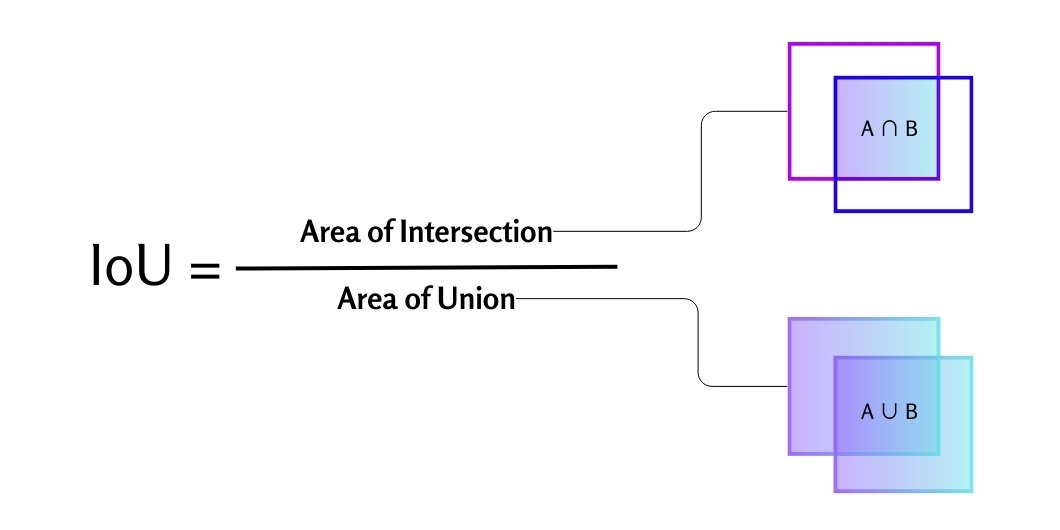 В терминах б-боксов IoU – это перекрытие между прогнозируемой рамкой и истинным прямоугольником из трейна. Получается, что если модель предсказывает высокое IoU, то она "верит" в то, что перекрытие будет большим, и, иными словами, сильнее уверена в существовании определенного б-бокса. И наоборот, если предсказывает низкое IoU, то уверена, что в ячейке объекта вообще нет. Именно поэтому в этой части лосса учитываются также клетки, в которых нет объектов (красивая единица с индексом
В терминах б-боксов IoU – это перекрытие между прогнозируемой рамкой и истинным прямоугольником из трейна. Получается, что если модель предсказывает высокое IoU, то она "верит" в то, что перекрытие будет большим, и, иными словами, сильнее уверена в существовании определенного б-бокса. И наоборот, если предсказывает низкое IoU, то уверена, что в ячейке объекта вообще нет. Именно поэтому в этой части лосса учитываются также клетки, в которых нет объектов (красивая единица с индексом noobj): на них мы учим модель давать меньше ложноположительных ответов. Такие ячейки мы взвешиваем с помощью константы λ_noobj, которая обычно примерно в 10 раз меньше λ_coord.
Таким образом, наша функция потерь "учит модель" правильно располагать в пространстве б-боксы и считать их размер, верно классифицировать найденные объекты, а также просто точно определять факт наличия объекта в ячейке и тем самым не переобучаться.
Итак, с трейном тоже разобрались. Осталось неочевидное: инференс. Предположим, мы обучили модель, и она дает нам на выходе некоторый тензор. Как собрать из него окончательный ответ, который должен содержать отфильтрованные б-боксы с метками классов?
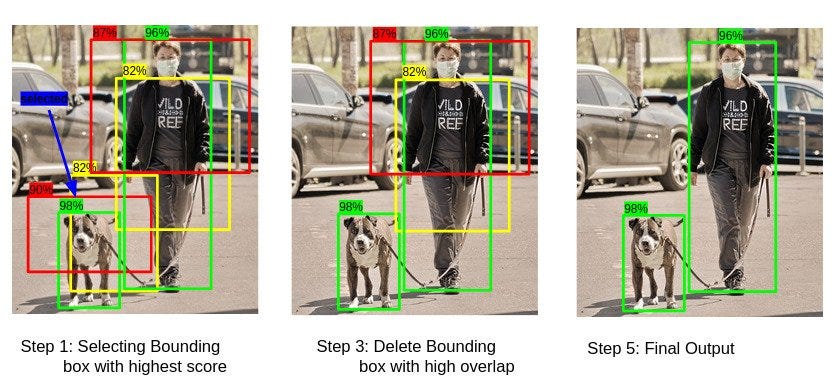
- Для начала, нужно привязать метки классов к определенным б-боксам. Ведь сейчас в каждом выходном векторе у нас две рамки, а вероятность для каждого класса всего одна. Чтобы их связать, нужно взять confidence score каждого б-бокса и перемножить его с каждой вероятностью класса. Так мы разветвим наши метки классификации и в итоге получим 7 * 7 * 2 = 98 прямоугольников, для каждого из которых определены лейблы классов, координаты центра, ширина, высота и IoU aka confidence score.
- Теперь нужно решить, какие из б-боксов мы оставим, а какие удалим. Для этого поступим просто: удалим все рамки, для которых IoU < 0.5 (то есть те, про которые модель скорее думает, что объекта в них нет).
- Но это не все. Ведь объект может не помещаться целиком только в одну из клеток, которые мы определили в самом начале. Тогда два, и даже три б-бокса из разных ячеек могут быть на самом деле единым б-боксом для одного и того же предмета. Тут на помощь приходит алгоритм Non-maximum Suppression. Он достаточно прост и изящен. Сначала мы берем список б-боксов, которые остались после пункта 2 и сортируем его по убыванию IoU, так, чтобы в начале были те б-боксы, в которых, как думает модель, расположены центры объектов. Затем будем по очереди брать самых "вероятных" кандидатов и находить все б-боксы, которые пересекаются с ними настолько, что IoU этого пересечения больше некоторого порога. Все такие б-боксы мы будем удалять и вычеркивать из исходного списка, и так до тех пор, пока список не опустеет, а у нас не появится набор финальных отфильтрованных б-боксов.
 Вот и все. Так работала первая версия YOLO.
Вот и все. Так работала первая версия YOLO.
Модель, конечно, получилась потрясающая и вызвала в 2016 ажиотаж. Но надо сказать, что в начале она все-таки зрительских симпатий не завоевала. Хотя модель была очень бодрая и работала в реальном времени, у нее были проблемы с метриками (63.4% на PASCAL против 73.2% у Faster R-CNN), и она плохо справлялась с объектами, которые накладывались друг на друга. Однако в последствие исследователи это исправили. Давайте посмотрим, как.
YOLOv2
Авторы статьи про YOLO быстро осознали недостатки своей модели и всего через несколько месяцев выпустили следующую версию – YOLOv2, а также небольшое ее расширение – YOLO9000. Модель не только вырвалась вперед на метриках, но и стала еще быстрее предыдущей версии, а также научилась распознавать в 450 раз (!) больше классов – отсюда и 9000 в названии.
Но давайте снова по-порядку. Во-первых, архитектура.
- Из нее удалили полносвязные детекционные слои в конце. На их место пришли свертки. Кроме того, из архитектуры убрали dropout. Вместо этого добавили batch normalization, который на тот момент показал себя хорошим инструментом для повышения сходимости и скорости обучения модели.
- Саму базовую архитектуру тоже поменяли с GoogLeNet на Darknet-19. Эта сеть состоит из меньшего количества слоев: 19 сверточных слоев против 22 у GoogLeNet. За счет такой подмены модель не просела на задачах в реальном времени.
- Если в предыдущей версии дообучение первых 20 классификационных слоев происходило на изображениях размером 224х224 из ImageNet, то вторая версия училась на изображениях более высокого качества: 448х448.
- При этом во время обучения архитектуры целиком разрешение входной картинки снизили до 416х416. Сделали это не просто так. Дело в том, что в этом случае изображение можно разделить на нечетное количество ячеек: тогда в середине изображения, где вероятность появления объекта больше всего, будет одна ячейка, а не четыре.
- Само количество ячеек тоже увеличили. Если в YOLO1 мы мысленно резали изображение на сетку 7х7, то теперь это была сетка 13х13. Технически это реализовали удалением одного слоя пуллинга, благодаря чему размер выходного тензора получился 13х13х125.
- Почему 125? Потому что в YOLO2 мы предсказываем метки классов уже не для всех боксов ячейки одновременно: теперь для каждого б-бокса вектор таких вероятностей свой. К тому же, теперь б-боксов на одну ячейку стало больше: раньше их было два, а теперь число увеличилось до пяти. Итого 5 б-боксов, для каждого координаты центра, ширина, высота, IoU и 20 меток классов: всего 125.
- Появились слои skip connection, которые предотвращают переобучение модели и делают ее более стабильной. Идея тут в том, что данные дублируются, и первая их часть проходит через определенные слои сети, а вторая их как бы пропускает. При этом такая "ленивая" часть, чтобы сохранить выходную размерность, просто разбивается в определенных пропорциях и прибавляется к своему близнецу, прошедшему через некоторое количество сверток.
 Перечисленное – далеко не конец. В YOLO 2 изменилась сама идея подхода к детекции объектов. Вместо традиционных б-боксов исследователи подчерпнули из Faster R-CNN задумку предсказывать anchor boxes (или якори). Вспомним, что Faster R-CNN – двухэтапный метод, и перед тем, как входные данные подаются в классификатор, у сети уже есть куча кандидатов на финальные б-боксы. Поэтому Faster R-CNN, в отличие от YOLOv1, не приходится предсказывать координаты с нуля: он предсказывает только сдвиги, на которые нужно переместить исходные боксы. Эта задача гораздо проще и надежнее с точки зрения точности ответов, поэтому было решено и в YOLOv2 добавить кандидатов (priors anchors), которые мы затем будем учиться передвигать.
Перечисленное – далеко не конец. В YOLO 2 изменилась сама идея подхода к детекции объектов. Вместо традиционных б-боксов исследователи подчерпнули из Faster R-CNN задумку предсказывать anchor boxes (или якори). Вспомним, что Faster R-CNN – двухэтапный метод, и перед тем, как входные данные подаются в классификатор, у сети уже есть куча кандидатов на финальные б-боксы. Поэтому Faster R-CNN, в отличие от YOLOv1, не приходится предсказывать координаты с нуля: он предсказывает только сдвиги, на которые нужно переместить исходные боксы. Эта задача гораздо проще и надежнее с точки зрения точности ответов, поэтому было решено и в YOLOv2 добавить кандидатов (priors anchors), которые мы затем будем учиться передвигать.
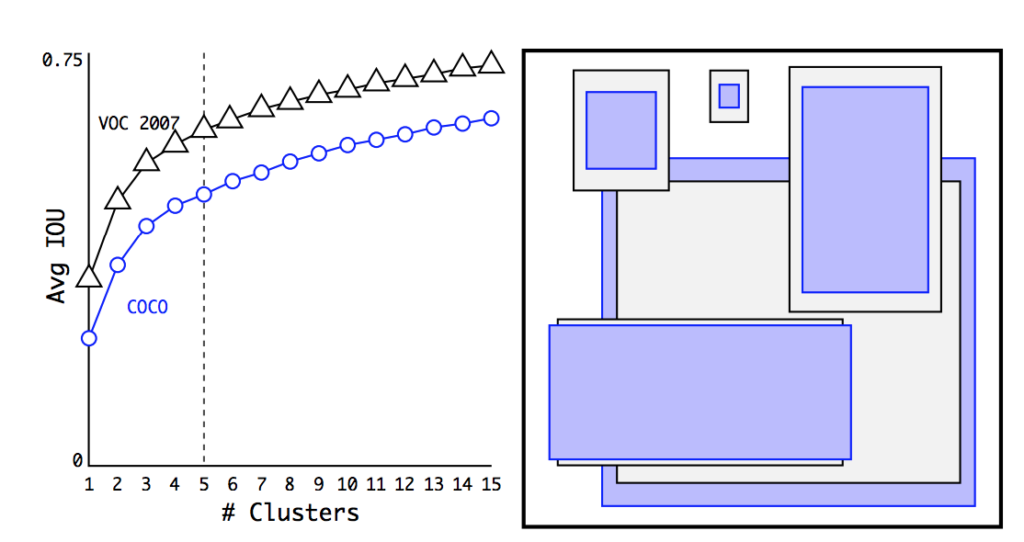
Очень интересным образом исследователи выбирали форму и количество исходных якорей. Для этого они обратились к размеченным датасетам COCO и VOC, и, грубо говоря, свели по ним статистику. В каждом из датасетов все существующие в нем б-боксы кластеризовали с помощью алгоритма K-means (только вместо евклидового расстояния в качестве меры близости использовалось IoU), и подсчитали, после какого количества кластеров точность выходит на плато. Оказалось, что после К = 5 mAP уже равно 61%, а затем растет не очень сильно. Затем в каждом из пяти полученных кластеров взяли усредненный б-бокс, и так получились те самые 5 якорей, предсказания для которых мы будем делать в каждой из 13х13 ячеек изображения.
 Получается, что и векторы, которые получаются на выходе для каждой ячейки, интерпретируются теперь по-другому? Да. Как мы уже упоминали, размер выходного тензора в YOLOv2 – 13х13х125: 5 якорей, для каждого 20 меток классов, confidence score и еще четыре фичи. Раньше этими четырьмя фичами были координаты центра, ширина и высота б-бокса. Теперь же это набор чисел
Получается, что и векторы, которые получаются на выходе для каждой ячейки, интерпретируются теперь по-другому? Да. Как мы уже упоминали, размер выходного тензора в YOLOv2 – 13х13х125: 5 якорей, для каждого 20 меток классов, confidence score и еще четыре фичи. Раньше этими четырьмя фичами были координаты центра, ширина и высота б-бокса. Теперь же это набор чисел t_x, t_y, t_w, t_h, которые отвечают за сдвиг якоря влево/вправо, вверх/вниз, изменение ширины и высоты соответсвенно. Конечные координаты б-бокса рассчитываются по такой логике (здесь c_x,c_y — координаты левого верхнего угла ячейки, p_w, p_h — исходные значения высоты и ширины якоря):
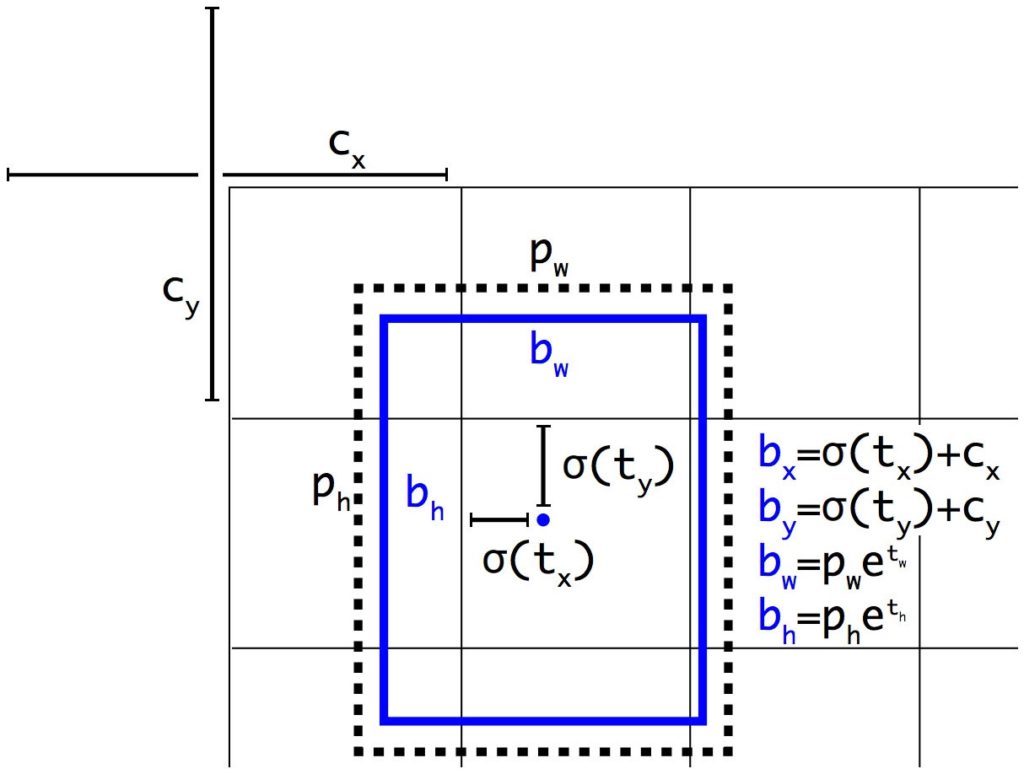 Сигмоида и экспонента здесь используются для стабилизации обучения, чтобы предсказания сети сразу рассчитывались только относительно определенной ячейки, а не относительно целого изображения.
Сигмоида и экспонента здесь используются для стабилизации обучения, чтобы предсказания сети сразу рассчитывались только относительно определенной ячейки, а не относительно целого изображения.
В обучении изменений, как таковых, не было. Все еще тот же лосс, все еще считаем IoU и в конце применяем Non-maximum Suppression.
А что там с YOLO9000? В нем вроде было 9000 классов, а не 20? Все верно, эти 9000 классов – это, на самом деле, 9000 лучших классов ImageNet, объединенные с классами из COCO. Правда, чтобы объединить эти два датасета, исследователям пришлось постараться: дело в том, что в ImageNet классов больше и они более конкретные. Например, если в ImageNet были классы "кукла", "плюшевый медвежонок", "мячик", то в COCO это все называлось просто "игрушка". Чтобы обойти проблему, была создана целая древовидная структура классов. Во время теста мы следуем от вершины к корню, и именно на корне считаем метрики, избегая взаимоисключения классов и связанных с этим коллапсов сети. При этом в этой версии количество якорей на ячейку сократили до трех, чтобы размер выходного тензора был не слишком велик.
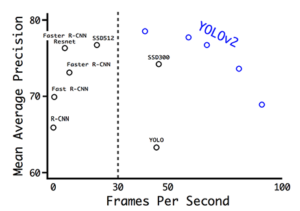
Что в итоге? В итоге YOLOv2 уже становится SOTA на PASCAL VOC и COCO. Сеть рвет всех конкурентов по метрикам и скорости, может работать на различных размерах изображений и в реальном времени. При 67 FPS YOLOv2 дает mAP 76.8, а при 40 FPS – 78.6 mAP, и это гораздо лучше Faster R-CNN и SSD.
 В общем, быстрее-выше-сильнее. Но и на этом исследователи не остановились. Еще через два года они выпустили третью версию модели.
В общем, быстрее-выше-сильнее. Но и на этом исследователи не остановились. Еще через два года они выпустили третью версию модели.
YOLOv3
YOLOv3 – это последняя версия модели, над которой работал ее создатель Джозаф Редмон, и последняя статья о YOLO, в которой он числится соавтором. В дальнейшем он покинул проект из-за того, что страдал из-за широкого применения своей модели в сфере обороны. В YOLOv3 никаких громких изменений не было, это скорее доработка YOLOv2 и исправление ошибок.
Во-первых, в YOLOv3 авторы расхрабрились и вместо Darknet-19 используют Darknet-53 – гораздо более глубокую сеть (53 сверточных слоя). Больше слоев – дольше работа, поэтому скорость модели немного просела. Зато удалось добиться очень значительного прироста к метрикам.
Во-вторых, у YOLOv3 на выходе уже не один большой тензор, а целых три.
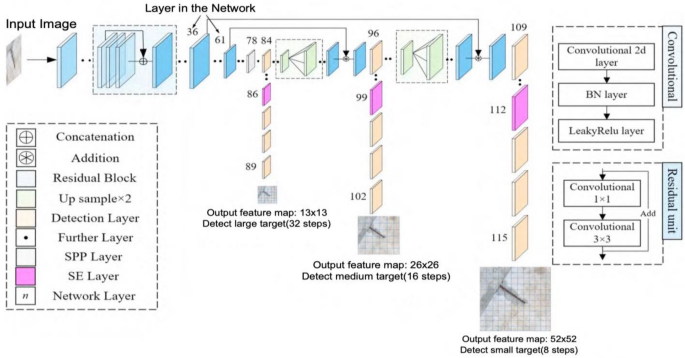 На картинке хорошо видно, что структура архитектуры как бы пирамидальная (кстати, в статье авторы как раз ссылаются на Feature Pyramid Networks). Первая фиче-мапа, которую мы получаем, имеет привычный крупный размер 13x13 (high level features). Следующая уже мельче – 26х26 (middle level features). Последняя – совсем мелкая – 52x52 (low level features). Смысл такой дележки в том, что чем мельче наша сетка, тем более мелкие объекты способна находить модель. Для больших же объектов легче использовать крупное разбиение. А если у нас есть и то, и то – сеть может работать на разных уровнях и хорошо отлавливать объекты и крупных, и мелких, и средних размеров.
На картинке хорошо видно, что структура архитектуры как бы пирамидальная (кстати, в статье авторы как раз ссылаются на Feature Pyramid Networks). Первая фиче-мапа, которую мы получаем, имеет привычный крупный размер 13x13 (high level features). Следующая уже мельче – 26х26 (middle level features). Последняя – совсем мелкая – 52x52 (low level features). Смысл такой дележки в том, что чем мельче наша сетка, тем более мелкие объекты способна находить модель. Для больших же объектов легче использовать крупное разбиение. А если у нас есть и то, и то – сеть может работать на разных уровнях и хорошо отлавливать объекты и крупных, и мелких, и средних размеров.
Небольшие изменения настигли и функцию потерь. Confidence score стал objectness score. Идейных изменений тут нет – это все еще степень уверенности модели в том, что в ячейке существует б-бокс. Но есть нюанс: это больше не совсем IoU, скорее IoU с нормализацией. Objectness score, в отличие от Confidence score, обязательно должен быть равен единице для того б-бокса, в котором модель уверена больше всего (то есть для того бокса, у которого пересечение с истинной рамкой максимальное среди всех предсказанных б-боксов). И параметр не просто переименовали, теперь он по-другому отражается в лоссе сети. Обновленная функция потерь выглядит так:
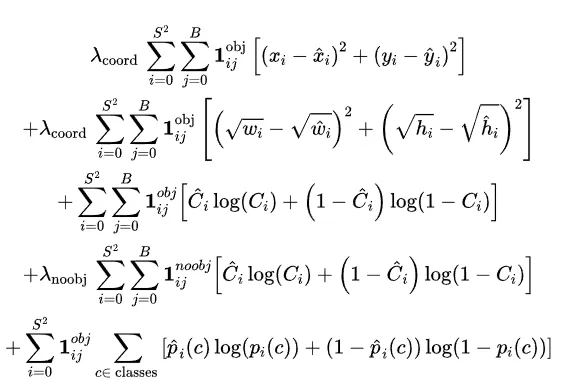 Первые две строки, то есть часть с координатами и шириной-длиной б-боксов, осталась такой же. А вот в последующих трех произошла подмена. Раньше для Confidence score и вероятностей классов использовался квадрат разности. Теперь его наконец-то убрали и заменили более стабильно зарекомендовавшей себя кросс-энтропией. Это классический классификационный лосс. Благодаря нему, в частности, стало возможно сделать из YOLO модель, которая умеет делать мульти-классификацию. Это значит, что предмету может быть назначено более одной метки (например, роза – это и "цветок", и "растение").
Первые две строки, то есть часть с координатами и шириной-длиной б-боксов, осталась такой же. А вот в последующих трех произошла подмена. Раньше для Confidence score и вероятностей классов использовался квадрат разности. Теперь его наконец-то убрали и заменили более стабильно зарекомендовавшей себя кросс-энтропией. Это классический классификационный лосс. Благодаря нему, в частности, стало возможно сделать из YOLO модель, которая умеет делать мульти-классификацию. Это значит, что предмету может быть назначено более одной метки (например, роза – это и "цветок", и "растение").
Несмотря на все эти изменения, на момент выхода модели в 2018 году она не смогла обогнать по метрикам все существующие решения. За два года появилась RetinaNet, которая оказалась точнее. Но стоит заметить, что популярность YOLO не пошла на спад благодаря ее скорости: она работала в 4 раза быстрее всех соперников!
YOLOv4
Несмотря на уход из проекта отца-основателя Джозафа Редмона, история архитектуры на этом не закончилась. Через два года, в 2020 году, мир увидел четвертую версию известной модели. В ее создании, кстати, принимал активное участие исследователь из России Алексей Бочковский. Статья представляет из себя большое путешествие по экспериментам, которые проводила команда. Давайте же узнаем, что в итоге внесло ощутимый вклад в качество новой версии детектора.
- Снова обновленная версия базовой архитектуры и снова новый вид Darknet'а. На этот раз CSPDarknet53. В этой сети такая же глубина, как и в прежней, но другая функция активации (Mish вместо ReLU) и вид skip connection (вместо привычных остаточных блоков тут используется ставший на тот момент модным метод Cross Stage Partial). Также в архитектуру добавили DropBlock – аналог дропаута для ядер свертки, который просто зануляет некоторые области изображения, делая их невидимыми для сети. Так сеть учится "смотреть шире" и догадываться о наличии объектов на изображении в условиях неполной информации.
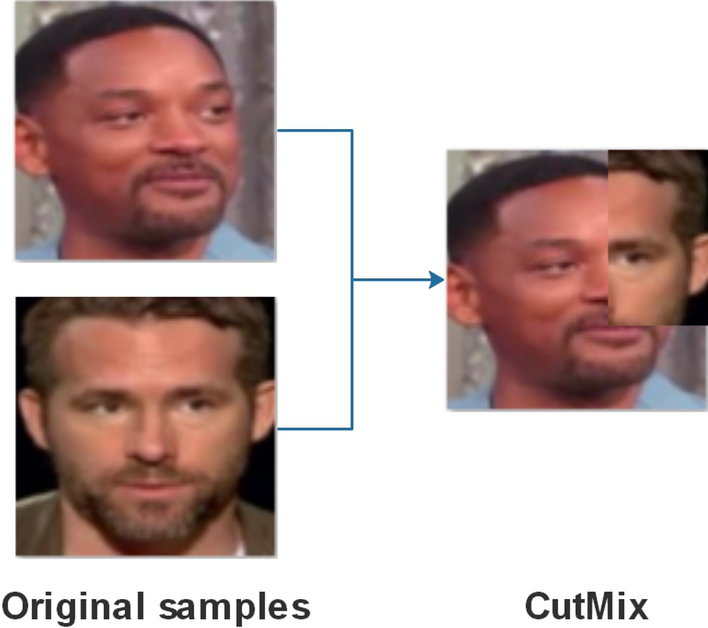
- В обучение тоже добавили много фокусов. Например, склеивали несколько картинок в один коллаж и учили на таких экземплярах сеть. Это называется Mosaic augmentation. Использовались и другие виды аугментации, такие как CutMix. Это когда часть изображения заменяется на другое изображение (например, кот с головой собаки). Лейблы в этом случае берутся от всех "принявших участие" классов с весом, определяемым пощадью, которую объект данного класса занимает на аугментированном изображении.
- Изменился подход к построению пирамидальной структуры сети. Авторы заметили, что хотя метод с тремя фиче-мапами улучшил работу модели с мелкими объектами, качество на крупных объектах, напротив, просело, потому что самый крупный выход модели не успевает зайти в сеть достаточно глубоко, и учится, исходя из этого, несколько поверхностно. Чтобы решить эту проблему, авторы добавили в модель дополнительные слои "обогащения" (на схеме внизу это область PANet). Обратите также внимание на лиловый слой в синей области, который называется SPP. Это тоже новый элемент сети – Spatial Pyramid Pooling. На самом деле это снова аналог скипконнекшена: несколько слоев пуллинга кучей применяются к исходному изображению для того, чтобы в фичах на выходе из Darknet'a осталось немного больше информации об исходном контексте.
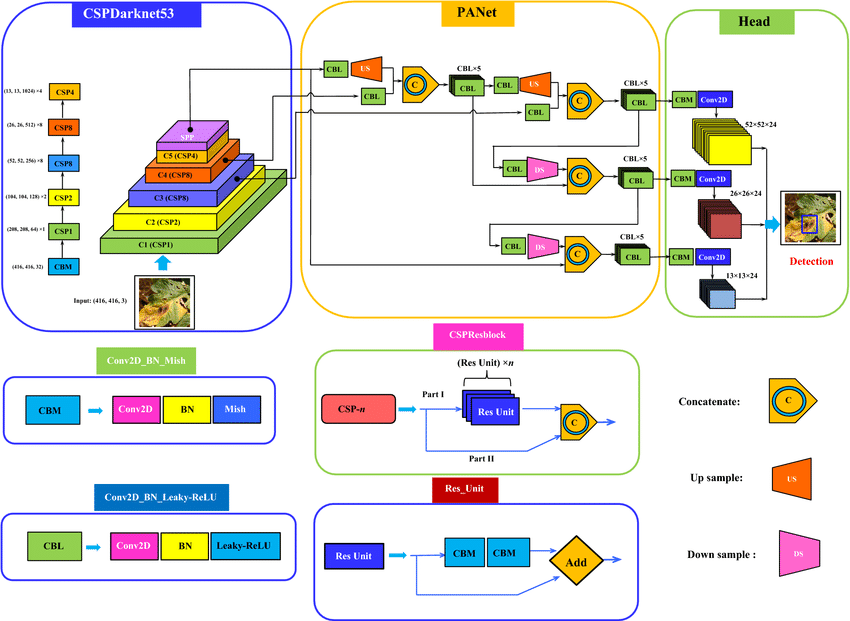
- Метод расчета конечных координат б-боксов ученые берут из YOLOv3, за исключением маленького изменения. Изменение состоит в добавлении нормировочной константы. Дело в том, что оказывается, формулы для расчета координат и сторон из версии 3 немного "сходят с ума", если центр объекта приближен к краю ячейки. При добавлении нормировки проблема нивелируется.
- Наконец, изменения постигли алгоритм пост-обработки, который не менялся, начиная с первой версии. Вместо Non-maximum Suppression теперь использовался Distance-IoU Non Maximum Suppression, который, как несложно догадаться, отличается от классического NMS применением метрики Distance-IoU вместо обычного IoU. Distance-IoU, помимо непосредственно перекрытия рамок, учитывает также расстояние между их центрами.
Мы перечислили 5 основных изменений, которые были добавлены в YOLO4. Помимо этого, исследователи экспериментировали с многими другими трюками и добавили в модель мелкие полезные фичи, вроде шедулера и Cross mini-Batch нормализации, подобрали лучшие гиперпараметры модели и даже пробовали интегрировать механизм внимания в отдельные слои сети.
Благодаря проделанной авторами работе YOLO стала на 20% лучше своих предыдущих версий и снова вырвалась в SOTA, сохранив при этом скорость.
YOLOv5
YOLOv5 – это история Золушки или Гадкого утенка во вселенной компьютерного зрения.
Она появилась чрезвычайно скоро после YOLOv4. Прошел всего месяц! "Не слишком ли это сказочные темпы для того, чтобы быть правдой?" – спросите вы. Да, это так. До этого момента каждая новая модель была действительно новой и несла в себе много свежих идей, изменения в архитектурах и подходах к детекции. Однако YOLOv5 показалась сообществу YOLOv4, просто переписанной на PyTorch. Вместе с реализацией модели даже не вышла научная статья. Да, надо упомянуть, что к созданию YOLOv5 не имел отношения ни один автор предыдущих моделей – новая версия была выпущена на тот момент не очень известной компанией Ultralytics. Компания обещала выпустить статью в течение нескольких месяцев, но... прошло 4 года, а статьи как не было, так и нет.
Это не все. Довольно сильно запятнал репутацию модели еще и тот факт, что в изначально опубликованных метриках, которые выпускала уже другая компания, Roboflow, были ошибки. Были проведены неверные замеры скорости моделей, и, как следствие, метрики и графики не отражали реальную картину. Многие исследователи и инженеры были настолько расстроены версией, что даже говорили, что она недостойна носить звание YOLOv5.
И, кстати, некоторое время Ultralytics действительно планировали сменить название, но... все как-то забылось. Компания смогла выйти сухой из воды, и, хотя статью они так и не выпустили, но зато сделали на тот момент одну из самых современных платформ для файнтюнинга и работы с YOLOv5 вообще. А еще они пообещали, что будут работать над улучшениями. И не обманули: два года они старательно работали над моделью и экосистемой, даже выпустили приложение.
 Да, за это время исследователями Ultralytics была проделана действительно большая работа: они обновили некоторые блоки модели (в частности, добавили больше С3-блоков, вместо SPP поставили SPPF), заменили активацию, добавили в лосс удачное взвешивание разных фиче-мап, придумали много новых аугментаций и инженерных трюков для улучшения производительности. Все это помогло поднять mAP аж на 6%, а в совокупности со MLOps средой, которую Ultralytics тоже постоянно обновляли и поддерживали, YOLOv5 стала настоящим всеобщим любимчиком! Многие используют именно эту версию до сих пор, а компания все еще постоянно ее обновляет.
Да, за это время исследователями Ultralytics была проделана действительно большая работа: они обновили некоторые блоки модели (в частности, добавили больше С3-блоков, вместо SPP поставили SPPF), заменили активацию, добавили в лосс удачное взвешивание разных фиче-мап, придумали много новых аугментаций и инженерных трюков для улучшения производительности. Все это помогло поднять mAP аж на 6%, а в совокупности со MLOps средой, которую Ultralytics тоже постоянно обновляли и поддерживали, YOLOv5 стала настоящим всеобщим любимчиком! Многие используют именно эту версию до сих пор, а компания все еще постоянно ее обновляет.
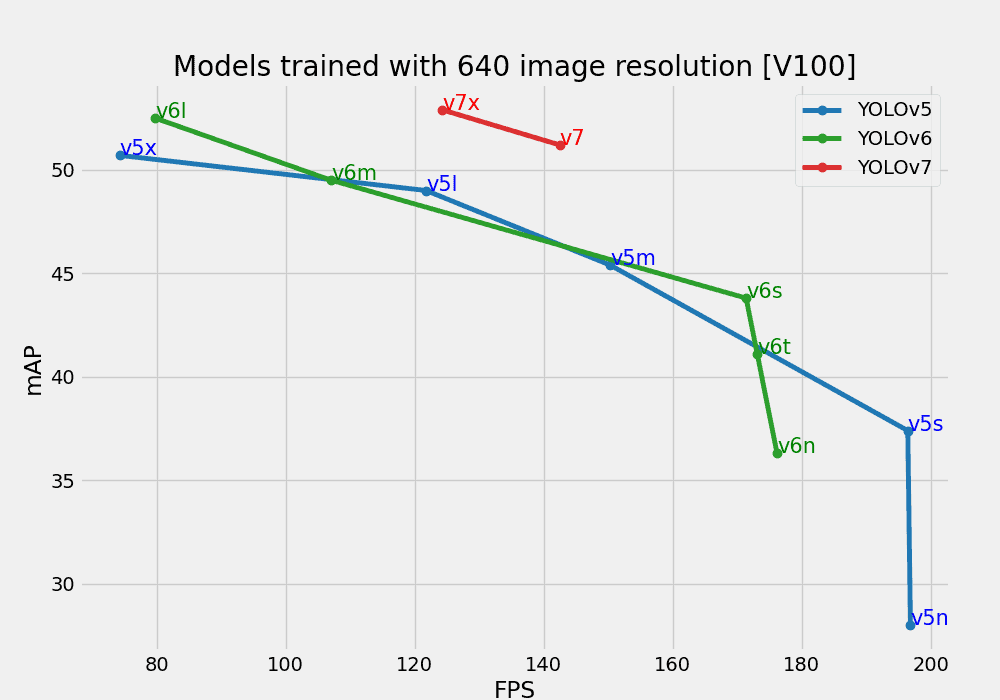
YOLOv6... или v7?
Вообще, честно было бы сначала рассказать про YOLOv7. Она, внезапно, вышла раньше шестой версии на целых два месяца (в июле 2022). Почему? Просто разработкой занимались разные лаборатории, которые, видимо, не смогли договориться относительно сроков и названий...
Тут нужно сделать небольшое лирические отступление и сказать, что за два года, помимо улучшений YOLOv5, разные группы ученых успели сделать для этой архитектуры очень многое: вышла YOLOX, YOLOR, три версии PP-YOLO и еще много мелких вариаций модели. Видимо, после истории с пятой версией все опасались называть модель v6 :)
И, кстати, шестая версия получилась не такой популярной, как пятая. Вот какие изменения предложили китайские исследователи:
- В YOLO 5 был заложен тренд на публикацию моделей разного размера, но отличались они только количеством параметров. А в YOLOv6 было предложено немного менять базовый бэкбон для моделей разного объема. Для маленьких моделей использовали RepBlock, а для моделей побольше – CSPStackRep.
- Также в модели снова обновили лосс: теперь он не учитывал якори, потому как модель сделали без якорей вообще. Эта идея позаимствована из YOLOX и называется Anchor-Free Decoupled Head. От якорей мы вернулись к подходу из первой версии: к предсказанию координат центра прямоугольника и длин его сторон. А те проблемы, которые были с ним связаны, решились с помощью идеи из четвертой YOLO – добавления нормировки относительно ячейки.
- Также ученые предложили использовать Efficient Decoupled Head и множество ухищрений для ускорения модели. Что там только не появилось: и Task Alignment Learning, и дистилляция, и квантизация, и репараметризация.
YOLOv6, кстати, прямо как YOLOv5, до сих пор постоянно обновляют и используют, но, в основном, только в Китае. Интересный факт: в этом году ее создатели выпустили уже шестую версию шестой версии.
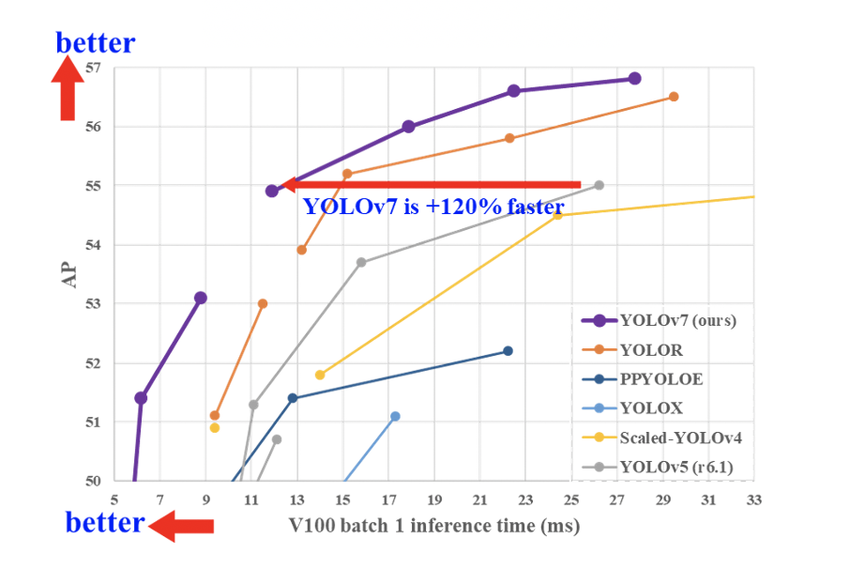
А в седьмой версии YOLO, хоть она и вышла раньше, обновления были несколько интереснее. В ее создании принимал участие Алексей Бочковский (тот самый, который создал четвертую версию) и создатель версии YOLOR. Команда, как видите, получилась сильная. Что же они предложили?
Во-первых, расширенную агрегацию слоев. Это, скорее, инженерный трюк, который позволяет сети обучаться и работать шустрее. Но и на качестве обучения это тоже сказывается, потому что слои аггрегации как бы "укорачивают" путь градиента по сети во время процесса обратного распространения, и масштабирование за счет этого происходит быстрее.
Во-вторых, новые техники скейлинга и репараметризации. Идея скейлинга похожа на то, что предложили китайские коллеги, только здесь параметры блоков меняются в зависимости от размеров модели не наугад, а учитывают глубину сети, ширину и разрешение входящих изображений.
В-третьих, новую голову Coarse-to-Fine в дополнение к трем уже существующим. Эта голова призвала контролировать переобучение за счет того, что результаты из нее влияют на лосс непосредственно, в отличие от остальных голов, которые проходят через какие-то блоки объединения.
В итоге шестая версия все-таки осталась позади седьмой, которая стала на момент выпуска новой SOTA скорости и качества детекторов.
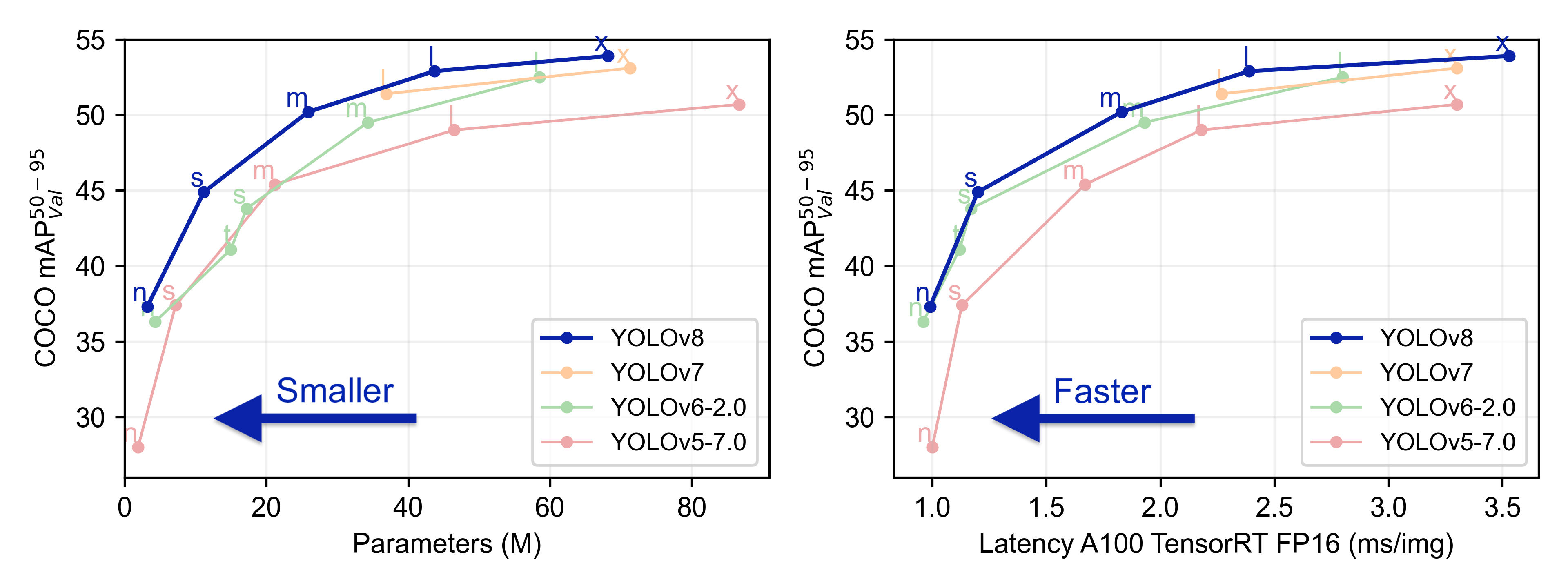
YOLOv8 – самая широкоиспользуемая модель линейки
В начале 2023 на арену снова вернулись Ultralytics, но на этот раз не с очередной версией пятой YOLO, а с новой YOLOv8. Но прежде, чем говорить о модели, давайте поговорим о том, что сделало восьмую модель такой популярной. Это не архитектура, не сказочные метрики, и даже не молниеносный инференс. Это совершенно новый репозиторий, который построен как единая платформа для обучения моделей детекции, сегментации и классификации. Компания выпустила пять моделей, каждая из которых может работать со всеми перечисленными задачами. Среди них была маленькая и шустрая YOLOv8 Nano и большая и самая точная YOLOv8 Extra Large (YOLOv8x). Все модели поддерживают много форматов экспорта и могут работать и на CPU, и на GPU. А еще YOLOv8 – это самое удобное API, которое совместимо и с командной строкой, и с Python.
В самой модели произошло немного изменений: новая Backbone сеть, функция потерь и Anchor-Free head. Для того, чтобы модель умела выполнять разные виды задач, ее обучали в несколько этапов на разных датасетах. Контрольные точки детекции обучены на основе COCO detection с разрешением 640. Чекпоинты сегментации – датасеты COCO сегментации с тем же разрешением. А для классификации датасет не менялся с первой версии, им так и остался ImageNet. Кстати, в восьмой версии слои классификации снова обучают на размере 224.
Ну и, конечно, без SOTA метрик никуда. Посмотрите, как ощутимо лучше показывает себя новая версия относительно предыдущих:
Последующие версии
Все последующие версии: YOLOv9, YOLOv10 и YOLOv11 тоже выпустила компания Ultralytics, сейчас у них негласная "монополия" на эту архитектуру. Последняя версия вышла совсем недавно: в октябре этого года. Однако сейчас обновление YOLO превратилось уже в скорее инженерную, а не исследовательскую задачу. Раз за разом разработчики оптимизируют инференс, сокращают количество параметров модели, работают над совместимость модели с новым железом и улучшают API.
Метрики все этого время тоже понемногу растут, но скорее за счет мелких исправлений, а не за счет ключевых изменений в архитектуре. Например, в YOLOv9 исследователи докрутили идею об агрегации слоев и ввели в использование GELAN – общую сеть агрегаций, а также добавили умный чекпоинтинг градиентов – PGI.
Сегодня YOLO – самая точная и эффективная модель, которую повсеместно используют для широкого спектра задач компьютерного зрения. Это одна из немногих архитектур глубокого обучения, которая спустя много лет после открытия остается любимой и применимой.
Надеемся, статья вам понравилась! Оставайтесь с Data Secrets, скоро вас ждет еще много интересного :)