
Сейчас рынок переживает небывалый бум LLM. Модели отлично (ну или почти всегда отлично) справляются с написанием кода, математикой, рассуждениями и другими сложными задачами. Однако есть неприятная корреляция: чем модель умнее, тем, как правило, она больше и тяжелее, и следовательно, тем больше ресурсов она ест. Поэтому в этом году в ресерче появился новый тренд: SLMs (small language models).
Это значит, что ученые стараются научиться разрабатывать небольшие языковые модели, которые достаточно эффективны во многих задачах, но при этом гораздо легче, доступнее и дешевле на инференсе. Другими словами, мы хотим сформировать "маленькие и удаленькие" копии таких моделей, как GPT-4, Claude 3.5 или Llama 3.1.
Одними из самых трендовых и активно изучаемых способов к разработке SLM являются дистилляция и прунинг. В этой статье мы на примере недавней работы Nvidia рассмотрим, как эти методы использовать, почему это работает и к чему приводит. Поехали!
Что такое дистилляция и прунинг
Идея дистилляции и прунинга схожая – это попытка получить желаемую модель не с помощью привычного всем обучения с нуля, а путем сжатия модели побольше. Таким образом создавались Llama 3.1 70B, Llama 3.1 8B, Minitron 8B и 4В, и, возможно, даже GPT4o-mini.
Итак, давайте начнем с теоретического фундамента.
- Прунинг – это процесс уменьшения количества параметров модели либо путем удаления слоев (прунинг в глубину), либо путем удаления нейронов, голов внимания и эмбеддингов (прунинг в ширину). Прунинг часто сопровождается дообучением. Это нужно для того, чтобы модель не потеряла в точности.
- Дистилляция – это когда мы переносим знания из большой сложной модели (учителя) в меньшую и более простую модель (ученика). Цель в том, чтобы создать модель пободрее и поменьше, но такую, которая сохраняет большую часть перформанса исходной.
Дистилляция в свою очередь тоже бывает разная:
- Первый вариант: синтетические данные, полученные из более крупной модели учителя, используются для файнтюнинга модели поменьше, которая уже была предобучена на чем-то другом. В этом случае модель поменьше обучают предсказывать только следующий токен, как бы повторяя за большой моделью. Это называется SDG finetuning.
- Второй и более классический вариант: модель-ученик учится предсказывать не только следующий токен, но также логиты и другие промежуточные состояния модели-учителя на трейне. Это обычно так и называют: Classical knowledge distillation.
В последнем случае результаты обычно лучше, потому что градиенты получаются более богатыми по наполнению. Другими словами, тут мы предсказываем не одну генерацию учителя, а целое распределение: как бы учим модель-ученика не машинально повторять, а понимать ход мыслей "наставника". Именно такая форма дистилляции использовалась Nvidia.
Подход
Ученые из Nvidia предложили не просто использовать прунинг или дистилляцию, а показали, как их можно объединить. Вот схема, которая впервые применялась ими для Nemotron – их собственной недавно выпущенной модели:
- Точка отправления – большая исходная модель. Например, в случае с Nemotron это была модель на 15В. К ней мы собираемся применять комбинированный прунинг, то есть резать как в ширину, так и в глубину. Для этого оценивается важность (importance) каждого элемента сети: каждого слоя, нейрона, головы внимания и эмбеддинг-канала. Далее все это ранжируется, и, начиная с наименее важных элементов, мы режем нашу сеть до тех пор, пока количество параметров не станет настолько маленьким, насколько мы захотим.
- Следом за прунингом идет фаза retraining'а получившейся модели. В данном случае такое обучение представляет из себя именно дистилляцию. Мы берем исходную модель в качестве учителя и обучаем получившегося на первом шаге запруненного "ученика".
- Перейти к первому шагу и повторить все заново. А потом можно еще и еще раз: процесс итерационный, и количество циклов зависит от того, насколько большой была исходная модель и насколько маленькой должна быть результативная.
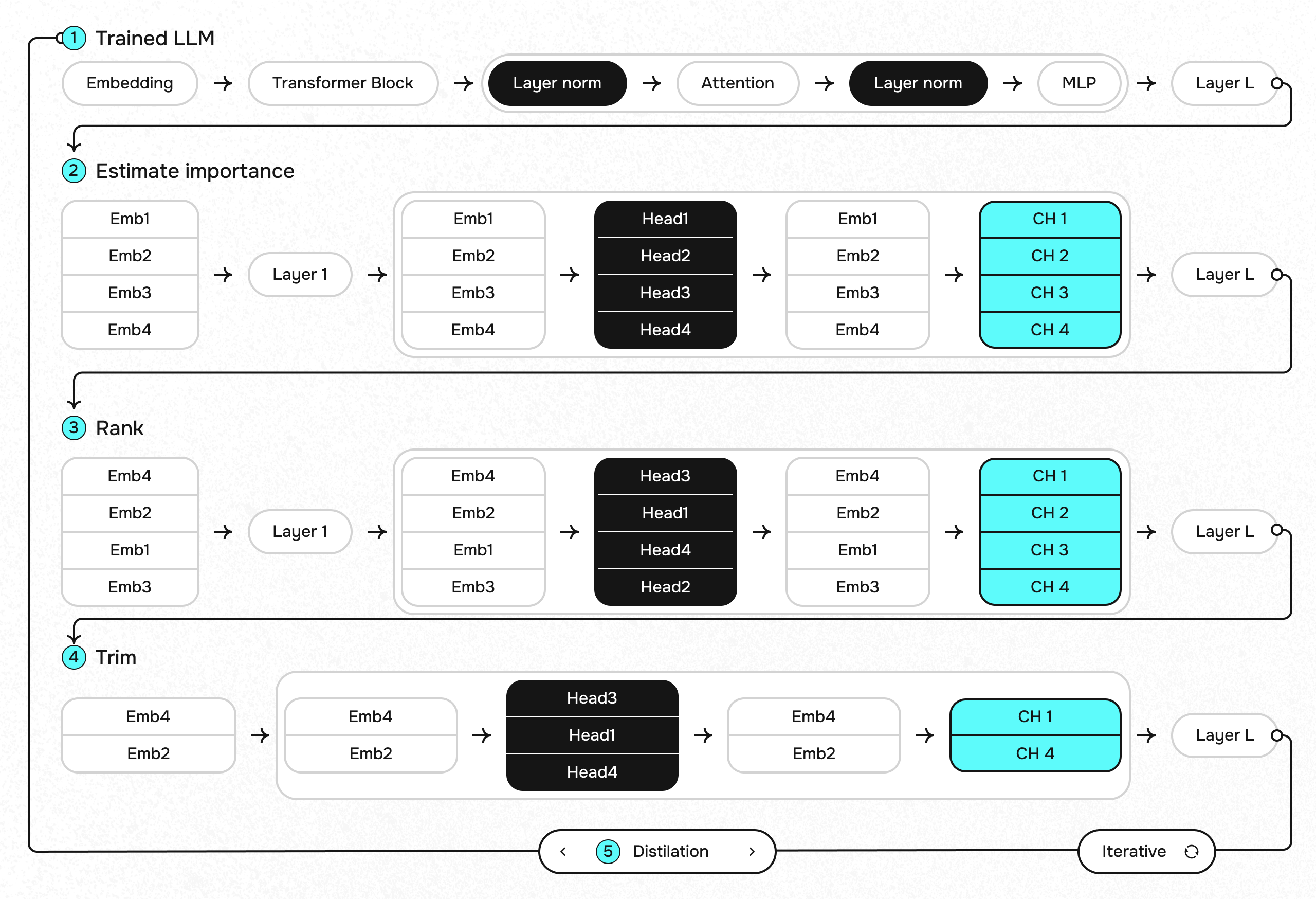 С прунингом вроде все ясно, но вот вопрос: как мы оцениваем importance каждого элемента сети?
С прунингом вроде все ясно, но вот вопрос: как мы оцениваем importance каждого элемента сети?
На самом деле очень просто. Нужно взять небольшую калибровочную выборку (в случае Nvidia всего 1024 сэмпла) и прогнать через сеть прямым проходом, сохраняя активации. Посмотрев затем на эти активации мы можем оценить, какие части своих внутренностей модель "задействует" больше всего. Кстати, ученые делают оговорку о том, что во время прунинга оценку важности элементов и отрезание частей от сетки теоретически можно чередовать. В то же время их эксперименты не показали никакого преимущества такого чередования, поэтому во имя экономии ресурсов они оценивали importance всего один раз, в самом начале.
С дистилляцией все прозрачнее и никаких новшеств тут нет. Вот картинка, которая хорошо иллюстрирует весь процесс:
.png) Мы описали подход, который использовался учеными Nvidia для облегчения их собственной модели – Nemotron. Вдохновленные успехом с этой LLM они решили применить примерно тот же самый алгоритм для свежей Llama 3.1. И (спойлер) внезапно получили SOTA-модель в своем размере!
Мы описали подход, который использовался учеными Nvidia для облегчения их собственной модели – Nemotron. Вдохновленные успехом с этой LLM они решили применить примерно тот же самый алгоритм для свежей Llama 3.1. И (спойлер) внезапно получили SOTA-модель в своем размере!
В случае с Llama 3.1 за основу бралась модель на 8В. Кроме того, на первом этапе применялся на смешанный прунинг, а сначала отдельно прунинг в глубину (обрезание слоев), а затем прунинг в ширину. Кстати, авторы отмечают, что если хочется выбрать всего один вид прунинга, то лучше выбирать прунинг в ширину: для облегчения и так относительно небольших моделей он показывает себя лучше.
Результаты
У исследователей получилось реализовать лучший сценарий: они оптимизировали модель и при этом сделали это так, что она почти не потеряла в точности. Внизу бенчмарки по сравнению с другими моделями примерно того же размера. И это при том, что получившаяся Llama-3.1-Minitron-4B примерно в 1,3 раза бодрее своего учителя на инференсе и обладает пропускной способностью в ~2.7 раз выше.
 Теперь понятно, почему дистилляция и прунинг – это новый тренд. Метрики выглядят не просто хорошо, а отлично. Да и в целом подход многообещающий.
Теперь понятно, почему дистилляция и прунинг – это новый тренд. Метрики выглядят не просто хорошо, а отлично. Да и в целом подход многообещающий.
Все модели уже доступны на HuggingFace: вот вариант с прунингом в ширину, а вот тут – в глубину. Вот здесь можно найти код проекта. А если хотите прочитать оригинальную статью – то вам сюда.