%20(1)%201.png&w=3840&q=75)
В любой e-commerce компании без ML – никуда. А особенно в такой крупной, как Авито. Это далеко не просто доска объявлений. Почти во все процессы компании сейчас вшит искусственный интеллект. Модерация товаров и пользователей, рекомендательные системы, автоматизация написания объявлений и ответов поддержки, классификация товаров, эффективность монетизации... Это только небольшая часть задач, которыми занимаются Data Scientist'ы и ML-инженеры в Авито.
.png) Ежедневно в базах данных компании логируется 30 млрд кликов, а ежемесячная аудитория Авито — порядка 60 млн человек, что составляет около 70% взрослого населения всей России. Конечно, работать с такими объемами данных непросто, тем более, что взять пример в решении сложной задачи с более крупных коллег не получится: компания является классифайдом №1 не только в России, но и в мире.
Ежедневно в базах данных компании логируется 30 млрд кликов, а ежемесячная аудитория Авито — порядка 60 млн человек, что составляет около 70% взрослого населения всей России. Конечно, работать с такими объемами данных непросто, тем более, что взять пример в решении сложной задачи с более крупных коллег не получится: компания является классифайдом №1 не только в России, но и в мире.
Так как же работают главные ML-механизмы Авито? Чтобы приоткрыть капот и посмотреть на внутренности процессов, мы поговорили с руководителями нескольких ведущих команд.
LLM
C помощью современных LLM можно решать огромное количество задач бизнеса. В Авито эта технология тоже активно используется.
 Анастасия Рысьмятова, руководитель разработки больших языковых моделей, работает в Авито уже больше 5 лет, год из которых руководит командой. Она рассказала нам о том, что с помощью LLM компания может решать проблему суммаризации отзывов, помогать пользователям общаться с покупателями или продавцами в чатах, а также упрощать жизнь агентам поддержки. Например, подсказывать им, как лучше поступить в той или иной ситуации и облегчать написание ответов, а в некоторых случаях даже полностью общаться с пользователями вместо сотрудника.
Анастасия Рысьмятова, руководитель разработки больших языковых моделей, работает в Авито уже больше 5 лет, год из которых руководит командой. Она рассказала нам о том, что с помощью LLM компания может решать проблему суммаризации отзывов, помогать пользователям общаться с покупателями или продавцами в чатах, а также упрощать жизнь агентам поддержки. Например, подсказывать им, как лучше поступить в той или иной ситуации и облегчать написание ответов, а в некоторых случаях даже полностью общаться с пользователями вместо сотрудника.
Многие LLM-решения разработчикам уже удалось внедрить в продакшен. Например, суммаризация чатов поддержки или генерация описания объявлений: когда пользователь подаёт объявление, модель подсказывает текст описания, чтобы вещь лучше продавалась. Пока что фича доступна только в категории fashion, но позже появится во всех разделах сервиса.
Такая задача – мультимодальная, так как в фотографиях, которые пользователь прикладывает в объявлению, содержится много-много полезной информации. Именно из-за этого исследователи используют специальную архитектуру. В общем-то она представляет из себя привычный трансформер, но энкодер вместо текста принимает на вход изображение. Необходимый текст (параметры предмета, которые указал пользователь) в свою очередь просто закатывается в промпт.
.png) Данные для обучения были взяты из собственного хранилища объявлений Авито. Так как далеко не все объявления из обучающей выборки были сформулированы правильно и понятно, до деплоя модель пришлось несколько раз пропускать через дополнительный цикл внутренней ручной валидации. Кроме того, в итоговую архитектуру продакшена внедрена постфильтрация, которая проверяет генерации на нарушения бизнес-правил и наличие галлюцинаций.
Данные для обучения были взяты из собственного хранилища объявлений Авито. Так как далеко не все объявления из обучающей выборки были сформулированы правильно и понятно, до деплоя модель пришлось несколько раз пропускать через дополнительный цикл внутренней ручной валидации. Кроме того, в итоговую архитектуру продакшена внедрена постфильтрация, которая проверяет генерации на нарушения бизнес-правил и наличие галлюцинаций.
На тестах оказалось, что функция приносит отличный uplift : заказов с доставкой стало на 1.7 процентных пункта больше, а это значит, что пользователи стали совершать больше покупок за счет лучшего понимания описания объявления. Среди продавцов в 60% случаев юзеры отмечают, что описание им понравилось.
Другая задача, которая уже внедрена во внутренние сервисы Авито – это извлечение параметров объявления. Оно используется для того, чтобы объединять объявления в мультиобъявления (это, например, одинаковые товары от одного продавца, но разного цвета или размера).
 Для всего перечисленного Авито использует собственную базовую модель, которая затем файнтюнится под разные виды задач. Конечно, свой прентрейн – это дорого и долго, но существующие опенсорсные модели часто плохо работают с русским языком, а еще недостаточно хорошо понимают доменную область компании.
Для всего перечисленного Авито использует собственную базовую модель, которая затем файнтюнится под разные виды задач. Конечно, свой прентрейн – это дорого и долго, но существующие опенсорсные модели часто плохо работают с русским языком, а еще недостаточно хорошо понимают доменную область компании.
В ядре LLM от Авито лежат веса модели Mistral 7B, которую адаптировали для русского языка с помощью Continual Pretraining. Данные для претрейна были собраны из различных открытых источников, всего получилось 1.5ТВ (1.1ТВ после фильтрации и дедупликации). Часть этих данных также пришлось пропустить во время обучения из-за взрывов лосса. Одна эпоха обучения занимала 15 дней на 72 GPU A100.
Еще одна проблема, которую нужно было решить, заключалась в токенизации модели. Токенизатор Mistral 7B, как и большинство других токенизаторов опенсорсных моделей, слабо справляется с русским языком. На практике это означает, что английские слова будут токенизироваться в небольшое количество токенов, а русские — в большое. Это делает модель медленнее и дороже на инференсе.
Подмена токенизатора модели – совсем не заурядная задача, но в Авито исследователи отыскали способ ее решить. Суть подхода заключается в том, что после подмены токенизатора нужно переопределить слой эмбеддингов. Для инициализации весов при этом происходит следующее: токены нового токенизатора прогоняются через старый токенизатор, затем из этих токенов извлекаются эмбеддинги, которые наконец усредняются. После инициализации вся остальная сеть замораживается, а слой эмбеддингов дополнительно дообучается на большом корпусе данных (~100GB). Но и на этом в Авито не остановились: чтобы повысить качество с новым токенизатором, разработчики после всех операций дополнительно разморозили всю сеть и прогнали ее через тот же корпус.
Результаты показали, что получившаяся модель действительно намного лучше справляется с русским языком, а также лучше показывает себя на внутренних бенчмарках компании (Moderation и relevance в таблице):
 В планах у компании тестировать еще больше бизнес-гипотез и путей использования генеративного ИИ на практике.
В планах у компании тестировать еще больше бизнес-гипотез и путей использования генеративного ИИ на практике.
"Авито — контентная площадка, мы точно будем интегрировать LLM и дальше. ИИ в Авито везде, и он развивался, постепенно охватывая разные этапы пользовательского пути, и для нас Gen AI / LLM — это эволюционная история развитии технологии." – говорит Анастасия.
Рекомендательные системы
Рекомендации занимают центральное место в продукте Авито, ведь это первое, что видит пользователь, заходя в приложение. Поэтому компания постоянно работает над улучшением качества моделей.
Чтобы узнать, как развиваются рекомендательные системы в Авито, мы обратились к Михаилу Каменщикову. Михаил работает в Авито с 2016 года, тогда в отделе было всего 4 человека. Сейчас команда выросла в 5 раз, и Михаил занимается менеджментом и стратегическим планированием.
 Михаил рассказал, как работает бесконечная лента объявлений, которую вы видите, заходя на главную страницу приложения. Такая лента полностью состоит из персональных рекомендаций, и через нее компания получает более 50% просмотров объявлений. Верхнеуровнево архитектура рекомендаций в ленте состоит из 5 моделей отбора кандидатов (некоторые из них онлайн, а некоторые оффлайн), ранкера и блендера.
Михаил рассказал, как работает бесконечная лента объявлений, которую вы видите, заходя на главную страницу приложения. Такая лента полностью состоит из персональных рекомендаций, и через нее компания получает более 50% просмотров объявлений. Верхнеуровнево архитектура рекомендаций в ленте состоит из 5 моделей отбора кандидатов (некоторые из них онлайн, а некоторые оффлайн), ранкера и блендера.
Ранжирование кандидатов происходит тоже привычно: с использованием дополнительных фичей юзеров и айтемов, таких как локация действий, близость вектора пользователей и вектора объявления или статистика привлекательности объявлений. Кстати говоря, поиски не влияют на рекомендации. Если вы просто сделаете поисковый запрос, ваши рекомендации не изменятся, а вот если откроете объявление — это даст сигнал моделям..png) С первого взгляда кажется: ничего особенного, обычная двухэтапная рексис. Но все не так просто. Основная задача, которую приходится решать инженерам уже долгое время – распространенная проблема единообразия рекомендаций.
С первого взгляда кажется: ничего особенного, обычная двухэтапная рексис. Но все не так просто. Основная задача, которую приходится решать инженерам уже долгое время – распространенная проблема единообразия рекомендаций.
"Допустим, пользователь активно интересуется авто, и не очень активно смотрит одежду. Если мы будем выбирать самые релевантные объявления при помощи модели, то в топе выдачи будут одни автомобили. Но наши эксперименты показали, что это ухудшает пользовательский опыт, - люди совершают меньше сделок. Чтобы решить эту проблему, мы используем алгоритм для смешивания ленты из разных категорий. Это позволяет разнообразить выдачу для пользователя. Но есть и другая неприятность: этот алгоритм не поможет, если пользователь интересовался только одной категорией, в этом случае вся его лента будет состоять только из неё. Эта проблема называется filter bubble: пользователь не может поменять свои рекомендации, если он взаимодействует только с ними. Отчасти эта проблема решается тем, что на Авито еще есть поиск, и пользователь может сформировать новый для себя интерес с его помощью. Но мы хотели, чтобы такой способ был и в ленте, поэтому решили развивать направления кросс-категорийных рекомендаций ", – рассказывает Михаил.
Это означает, что помимо того, что лежит в области прямых интересов пользователя, в Авито вам рекомендуют также товары из других категорий. Внутри каждой категории работает отдельная модель, ранжирующая объявления, а лента в свою очередь набирается из категорий динамически рандомизировано (см. схему ниже). При этом вероятность выбора категорий определяется интересом пользователя, то есть количеством действий, которые он совершил в той или иной категории. Понятно, что такая эвристика работает с точки зрения метрик точности хуже, чем обычная модель ранжирования, однако на AB-тестах показывает себя лучше, дольше задерживая пользователя в ленте.
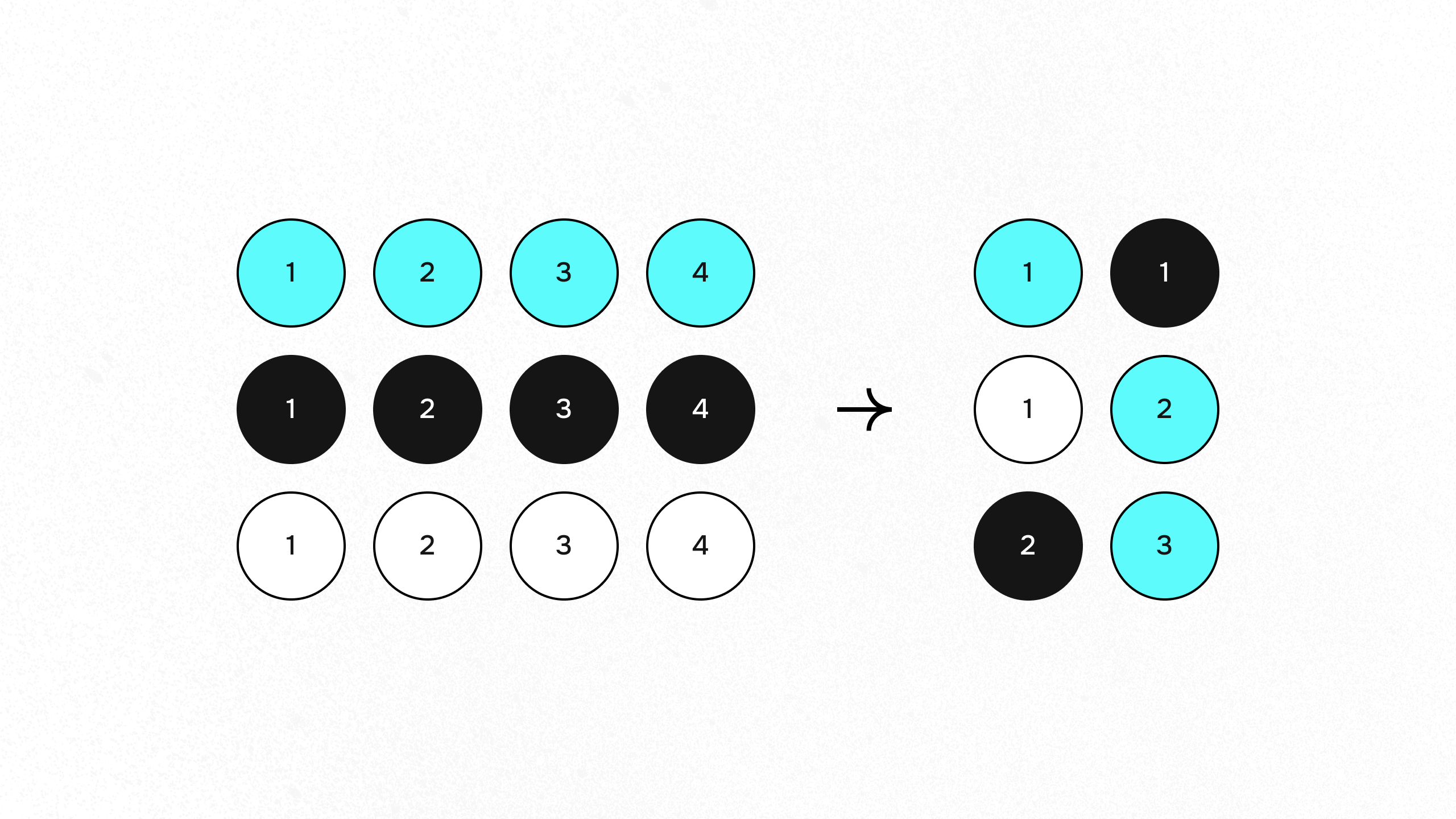 Кроме того, к персональным рекомендациям, о которых мы только что узнали, добавлена так называемая mic2mic модель. Mic – сокращенно от "микрокатегория". Это сущность, похожая на категорию, но более мелкая. Например, категорией может быть "обувь", а микрокатегорией – "мужские кроссовки".
Кроме того, к персональным рекомендациям, о которых мы только что узнали, добавлена так называемая mic2mic модель. Mic – сокращенно от "микрокатегория". Это сущность, похожая на категорию, но более мелкая. Например, категорией может быть "обувь", а микрокатегорией – "мужские кроссовки".
Особенность mic2mic в том, что она предсказывает интерес не к айтемам, а как раз к таким микрокатегориям. Раньше для этого использовалась коллаборативная фильтрация, в основе которой лежала простая квадратная матрица перехода пользователя между категориями. При перемножении на вектор действий пользователя по микрокатегориям такая матрица давала вектор его предсказанных интересов. Обучался алгоритм градиентным спуском с оптимизацией logloss по вектору интересов. Кстати, затем на проде из этого вектора выбирался не просто топ микрокатегорий: чтобы добавить еще больше новизны, выбор осуществлялся опять же взвешенно-случайно.
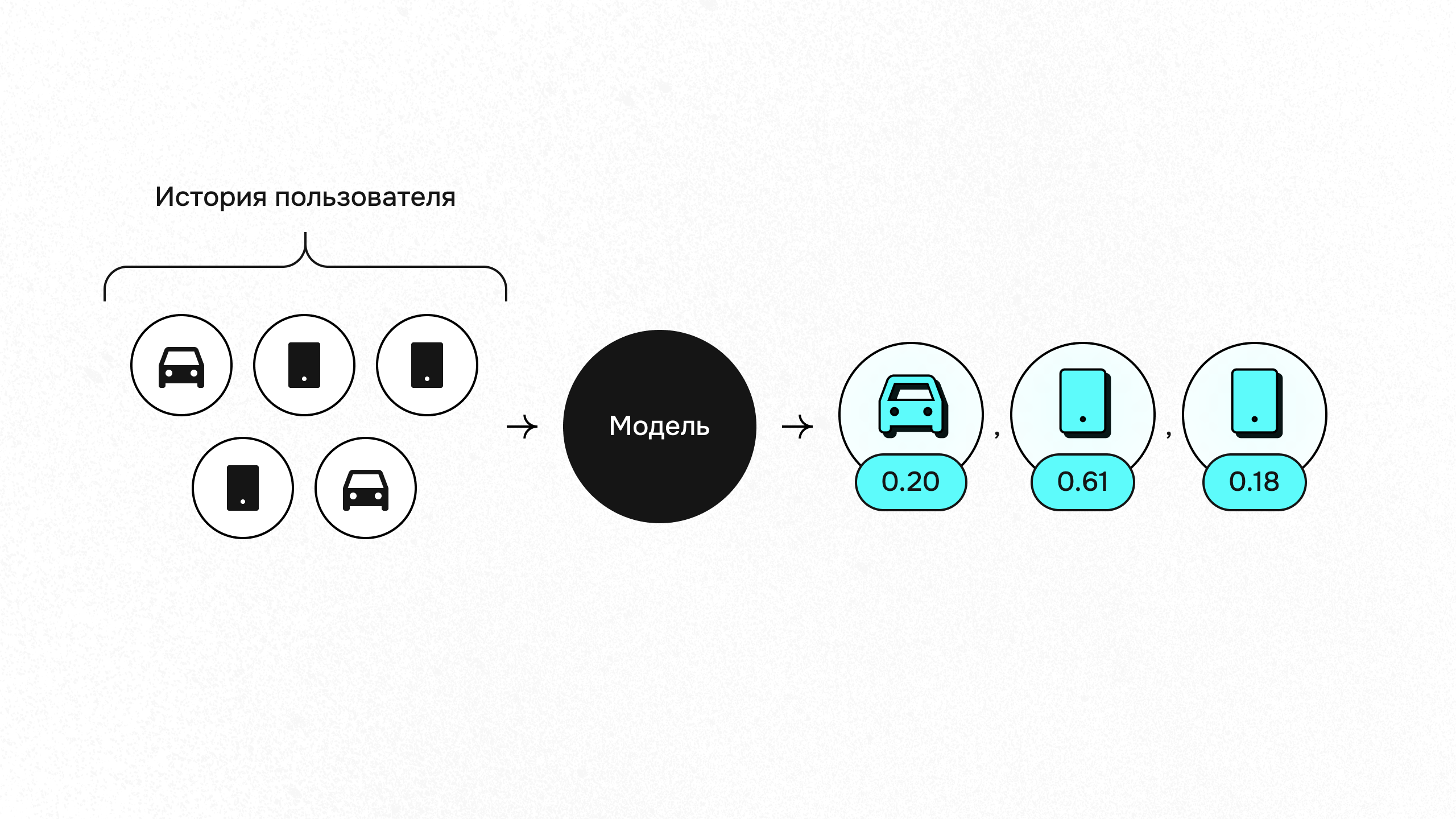 Даже на таком простом бейзлайне основные бизнес-метрики на проде уже выросли на 1-1.5%. Однако на сегодняшний день в продакшене работает еще более интересная модель – SasRec. Ее ключевое отличие от матрицы состоит в том, что она умеет учитывать последовательность действий пользователя, а не просто скидывает их "в кучу". Кроме того, для такой модели меняется оффлайн приемка: теперь метрики ранжирования высчитываются для задачи предсказания next item (в нашем случае это микрокатегория), а не на предсказаниях модели на некоторое количество дней вперед.
Даже на таком простом бейзлайне основные бизнес-метрики на проде уже выросли на 1-1.5%. Однако на сегодняшний день в продакшене работает еще более интересная модель – SasRec. Ее ключевое отличие от матрицы состоит в том, что она умеет учитывать последовательность действий пользователя, а не просто скидывает их "в кучу". Кроме того, для такой модели меняется оффлайн приемка: теперь метрики ранжирования высчитываются для задачи предсказания next item (в нашем случае это микрокатегория), а не на предсказаниях модели на некоторое количество дней вперед.
В будущем команда также планирует продолжать путь в сторону Deep Learning моделей и тестировать новые гипотезы. Михаил говорит: "Мы видим два способа развиваться: улучшать то, что есть, или вводить серьёзные изменения с новыми архитектурами. Второе — более рискованный путь, но выхлоп будет больше на длинной дистанции. Мы занимаемся и тем, и другим, команда растёт, также мы стараемся выходить за пределы главной страницы и внедряем персонализацию в другие разделы. Рано или поздно всё так или иначе будет персонализировано".
Монетизация
Алгоритмы монетизации – это одна из уникальных и самых интересных систем в Авито. Когда продавец обращается к компании за тем, чтобы продвинуть свой продукт, перед нами возникает сложный выбор. С одной стороны, нужно растить выручку, а с другой – заботиться о положительном опыте пользователей. Другими словами, за справедливые для продавца деньги мы должны продвинуть его продукт в ленте так, чтобы максимизировать свою выручку и отклики на товар, и при этом не испортить рекомендации и опыт поиска покупателям.
Про то, как компания справляется с такими сложностями, рассказал Егор Самосват – руководитель юнита эффективности монетизации. Егор уже более десяти лет занимается рекламными технологиями, и год руководит эффективностью монетизации в Авито.
 "У нас действует принцип абсолютного приоритета пользовательского опыта. Нам важно смотреть, как мы влияем на опыт покупателей и продавцов. В этом смысле мы близки к классической системе рекомендаций, но добавляется монетизационная специфика. Нам нужно, чтобы модели не только хорошо ранжировали, но и приносили прибыль. " – говорит Егор.
"У нас действует принцип абсолютного приоритета пользовательского опыта. Нам важно смотреть, как мы влияем на опыт покупателей и продавцов. В этом смысле мы близки к классической системе рекомендаций, но добавляется монетизационная специфика. Нам нужно, чтобы модели не только хорошо ранжировали, но и приносили прибыль. " – говорит Егор.
Один из самых интересных выводов из опыта команды такой: монетизация повышает эффективность системы. Получается win2win: продавцы начинают лучше заботиться о продвижении своего товара и поиске своих покупателей, в итоге зарабатывая на продажах больше, и при этом выручка Авито тоже растет. Это похоже на парадокс Браеса и, говоря математически, вводя монетизацию, мы приближаем равновесие Нэша в системе к оптимальному.
Однако при всех прелестях монетизации грамотное ее построение остается нетривиальной задачей. Например, возникает проблема сложности оценки нововведений. Даже если на короткой дистанции новая механика покажет рост бизнес-метрик и выручки, через какое-то время покупателей может стать меньше, а продавцы могут снизить свои бюджеты на продвижение. Из-за таких рисков в Авито используются специальные split-тесты и региональные тесты, которые являются продвинутыми аналогами A/B и учитывают доменную специфику задачи.
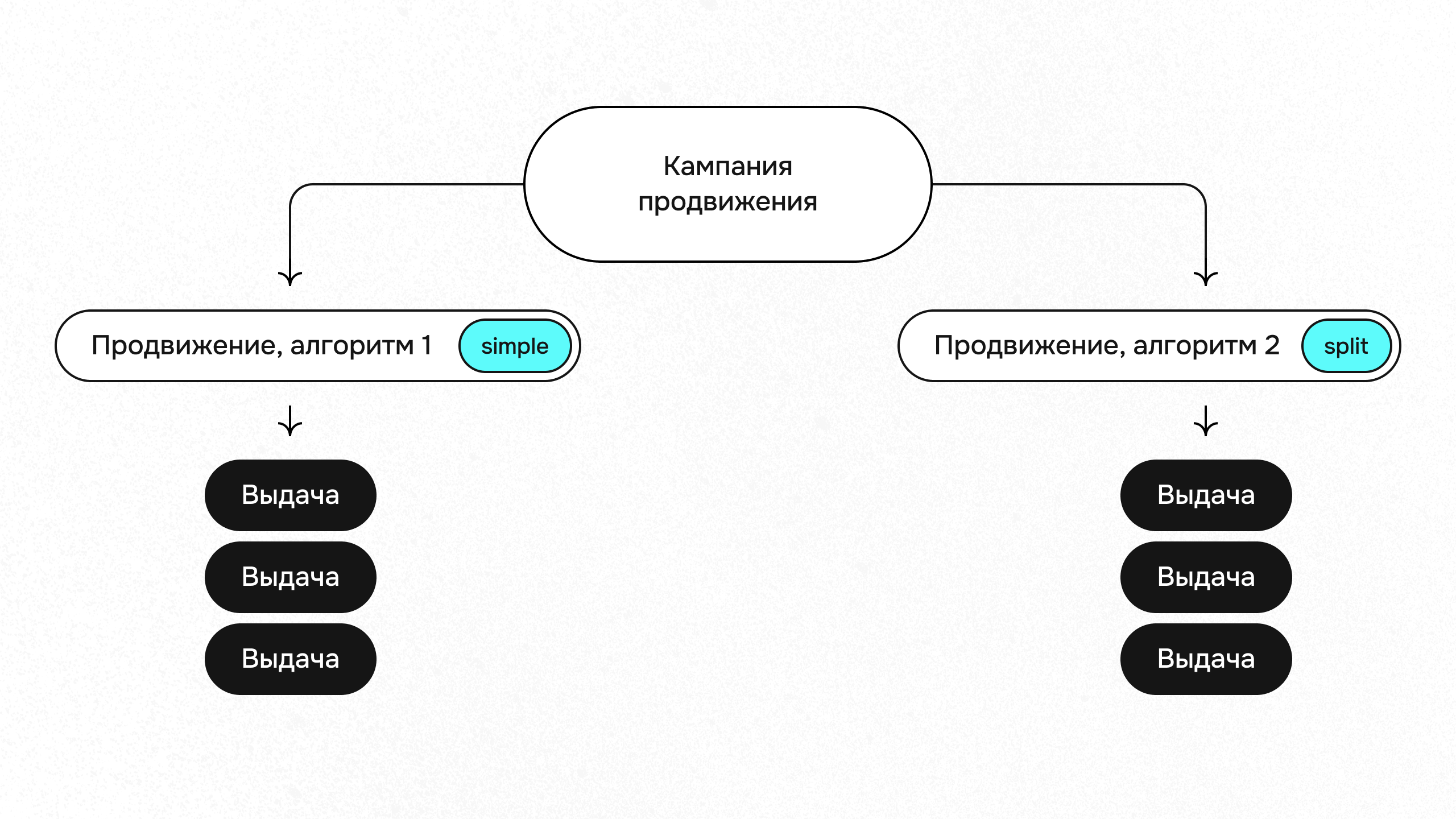 В самом ядре монетизации Авито – математический аукцион. На заре компании вместо этого использовались так называемые бусты за деньги. Оплачиваешь продвижение — поднимаешься в выдаче. Оказалось, что эти бусты давали недостаточную эластичность продуктам, то есть когда на конкурентном рынке все покупали продвижение — эффект продвижения снижался. Покупатели пробовали вкладывать всё больше денег в продвижения, но объявления в итоге выходили на плато и не получали преференций. Аукционы призваны сделать так, чтобы трафик справедливо распределялся между продавцами и отклик на покупку продвижения был более явным.
В самом ядре монетизации Авито – математический аукцион. На заре компании вместо этого использовались так называемые бусты за деньги. Оплачиваешь продвижение — поднимаешься в выдаче. Оказалось, что эти бусты давали недостаточную эластичность продуктам, то есть когда на конкурентном рынке все покупали продвижение — эффект продвижения снижался. Покупатели пробовали вкладывать всё больше денег в продвижения, но объявления в итоге выходили на плато и не получали преференций. Аукционы призваны сделать так, чтобы трафик справедливо распределялся между продавцами и отклик на покупку продвижения был более явным.
О существовании аукциона как механизма продавцы могут даже не догадываться, но именно аукционное ранжирование используется, когда нужно отсортировать в выдаче все объявления, для которых было куплено продвижение. В математических терминах это первая стадия классического аукциона — стадия allocation, когда все участники аукциона выставляют ставки, и система решает, какие объявления на какие места встанут. В случае Авито настоящих ставок (в данном случае это ставка за клик, Bid) участники не ставят, это делает за них автобидинг. Чтобы отранжировать участников аукциона, Bid умножается на CTR (Click-throught Rate), то есть вероятность клика при условии показа. И именно СTR должна научиться предсказывать наша модель.
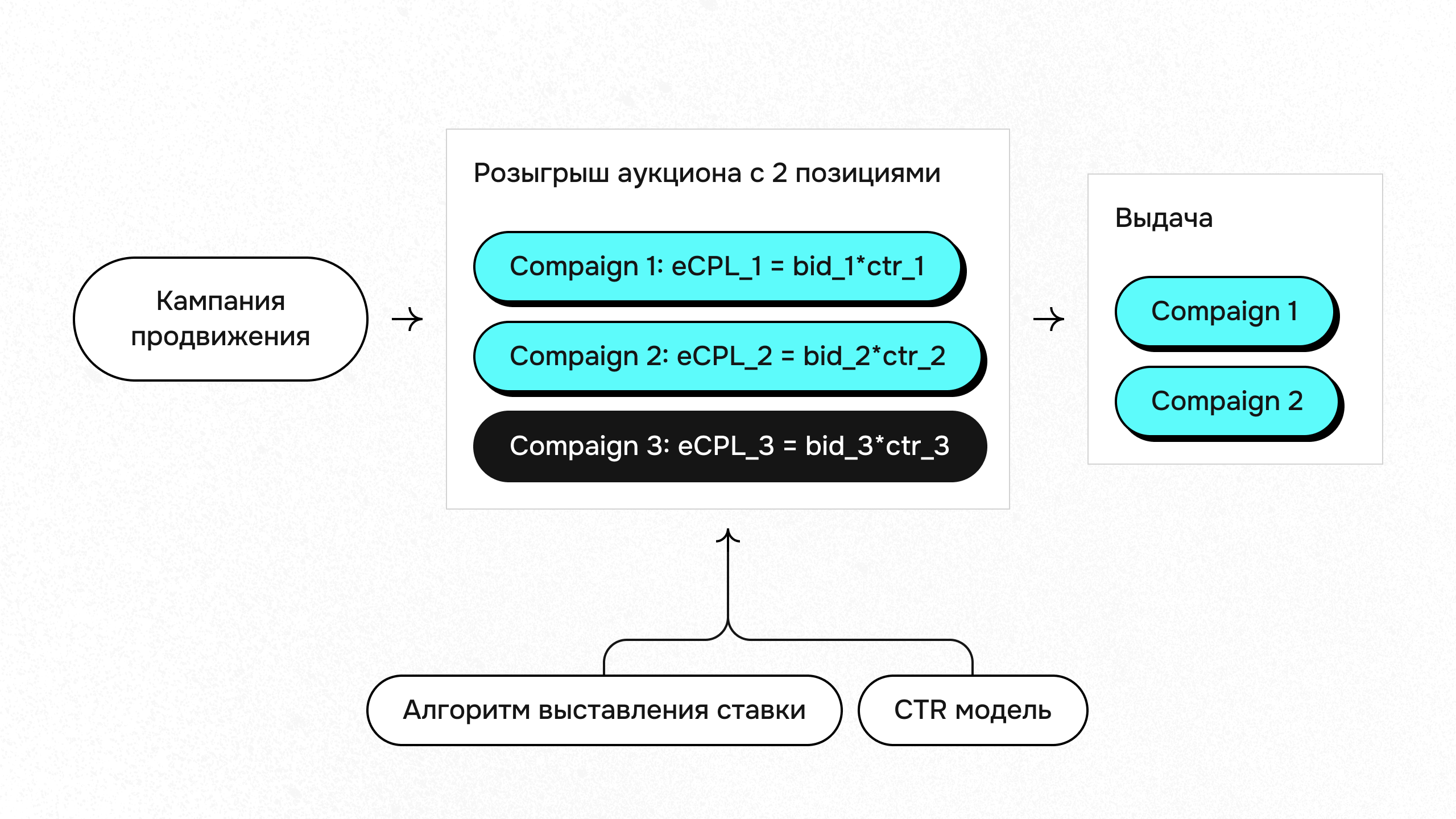 Обратите внимание, что такую задачу можно решать и как регрессию, и как классификацию. В связи с этим возникает еще одна дилемма: какие метрики для оффлайна и онлайна выбрать, чтобы оценить модель более точно? Это могут быть и регрессионные метрики, и NDCG из рексис, и ROC-AUC, и precision c recall, и калибровка, и даже выручка. В Авито нашли баланс и на онлайне больше внимания отдают бизнес-метрикам – выручке с аукциона и количество аукционных кликов, – а на оффлайне оценивают более ML-ные Stratified AUC и калибровку.
Обратите внимание, что такую задачу можно решать и как регрессию, и как классификацию. В связи с этим возникает еще одна дилемма: какие метрики для оффлайна и онлайна выбрать, чтобы оценить модель более точно? Это могут быть и регрессионные метрики, и NDCG из рексис, и ROC-AUC, и precision c recall, и калибровка, и даже выручка. В Авито нашли баланс и на онлайне больше внимания отдают бизнес-метрикам – выручке с аукциона и количество аукционных кликов, – а на оффлайне оценивают более ML-ные Stratified AUC и калибровку.
Оказалось, что метрики – это очень важно. Сам переход на новую правильную систему оценивания моделей помог команде монетизации поднять аукционную выручку на 5%. Мощный результат, правда?
Кроме CTR-моделей, команда Егора также работает над алгоритмом автобидинга, который выставляет ставку на аукцион, и над самим типом аукциона. От типа аукциона зависит вторая его фаза, которая следует за этапом ранжирования участников – фаза payment, на которой решается, кто сколько заплатит.
Возьмём, например, аукцион первой цены, в котором платёж равен ставке: человек может попробовать поставить 10 или 5 рублей за просмотр. Если его объявление всё равно окажется на первом месте, то ему не захочется переплачивать и он захочет искать минимальную ставку, обеспечивающую победу в аукционе. Эту проблему решает аукцион второй цены — он берёт столько денег, чтобы объявление всё равно осталось на определённой позиции.
Но иногда продавцам выгодно не просто поставить такую ставку, которая сохранит объявление на заданной позиции, а посчитать ставку так, чтобы оказаться на второй или третьей позиции, потому что там просмотры будут дешевле. VCG-аукцион, являющийся обобщением аукциона второй цены, решает эту проблему — он берёт больше денег только за дополнительный трафик, а за остальной трафик ты платишь столько, сколько платил бы при меньших ставках.
В продакшене Авито из всего многообразия этих алгоритмов реализовано сразу несколько, в зависимости от продукта. Однако сейчас команда готовится на повсеместный переход на аукцион первой цены — это позволит сделать единое ценообразование и упростить механизмы.
Что еще?
Те задачи, о которых мы рассказали в статье – это далеко не весь список того, чем в Авито занимаются ML-инженеры и Data Scientist'ы. Если хотите познакомиться с инфраструктурой компании еще ближе – советуем посмотреть большое видео с Data Fest 2024, который проходил в гостях у Авито.
Кроме того, у компании есть сайт, блог на Хабр и Телеграм-канал. В этих источниках компания постоянно делится новостями и техническими статьями. А если вас заинтересовала возможность поработать в Авито над интересными ML-задачами, то обратите внимание на вот эту страницу с вакансиями, а также на возможность пройти стажировку или поступить в Data Science магистратуру компании.