
В соавторстве статьи Константин Воронцов – доктор физико-математических наук, преподаватель ШАД и МГУ, автор метода ARTM и создатель библиотеки BigARTM для тематического моделирования.
Какую цель мы обычно преследуем, когда анализируем данные? Верно, нам нужно извлечь из них некоторые выводы и инсайты. Если данные структурированы – например, представлены в виде таблиц, – сделать это можно с помощью классических статистических методов и простых алгоритмов. Но что делать, если данные не имеют четкой структуры? Что, если это куча текстовых документов, или изображений, или молекулы белков? Как выявлять в таких структурах паттерны, извлекать из них значимую информацию или осуществлять по ним поиск?
На помощь приходит тематическое моделирование. Это технология статистического анализа текстов для автоматического выявления тематики в больших коллекциях документов. Тематическая модель определяет, к каким темам относится каждый документ, и какими словами описывается каждая тема. Для этого не требуется никакой разметки, баз знаний или тезаурусов. Обучение происходит без учителя, темы строятся автоматически.
Может показаться, что с появлением больших языковых моделей тематическое моделирование ушло в прошлое. Но нет, с помощью этой технологии все еще решают огромное количество задач и проблем. Например:
- задача построения профилей интересов пользователей в рекомендательных системах
- задача категоризации интентов собеседника и управления диалогом в системах разговорного интеллекта
- задача поиска изображений по тексту и текстов по изображениям
- задача поиска аномального поведения объектов в видеопотоке
- задача разведочного поиска в электронных библиотеках (это поиск по смыслу, а не по ключевым словам)
- задача обнаружения и отслеживания событий в новостных потоках
- задача поиска мотивов в нуклеотидных и аминокислотных последовательностях.
В статье мы разберемся с ключевыми концепциями тематического моделирования и основными архитектурами моделей этой области. Будет теория и много практики на интерфейсе библиотеки BigARTM. Кстати, игривое существо на картинке – это придуманный разработчиками тотемный персонаж библиотеки, и мы встретимся с ним еще не раз. 
Что такое тематическое моделирование
Тематическое моделирование отвечает на вопросы «о чём этот текст», «какие общие темы есть у этих текстов» и «какими словами представлена эта тема». Задача тематической модели, или, точнее, вероятностной тематической модели состоит в том, чтобы определить вероятность того, что документ или некоторое слово принадлежит к той или иной теме.
Говоря языком классического машинного обучения, тематическое моделирование похоже на кластеризацию документов. Только, в отличие от привычной задачи жесткой кластеризации, текст может относится к нескольким темам одновременно, как и отдельно взятое слово.
Кстати, на самом деле мы оперируем не совсем словами, а термами. Термы могут быть словом, фразой или частью слова. Это, по аналогии с токенизацией в языковых моделях, зависит от предобработки текста.
Чтобы окончательно расставить все точки над i, осталось обсудить математическую постановку задачи. Формально, у нас есть три конечных множества: множество текстовых документов D, словарь всех употребляемых в них термов W и множество тем T. При этом D и W известны нам заранее, а вот T – нет (напоминаем, что задача относится к обучению без учителя). Рассмотрим условные вероятности φ = p(w|t) и θ = p(t|d). Они означают соответственно вероятности того, что «терм w связан с темой t» и того, что «документ d относится к теме t». Эти вероятности нам неизвестны и наша задача сводится к приближению их оценок. Чем точнее такая оценка – тем лучше мы понимаем генеральную совокупность и, следовательно, распределяем тексты и термы по темам.
Но есть и такие оценки, которые нам уже даны. Это оценки вероятностей p(w|d), и на самом деле это просто частоты терминов в документах. Именно на основе этих оценок мы в дальнейшем будем строить вероятностную модель. Все дело в том, что имеет место равенство: 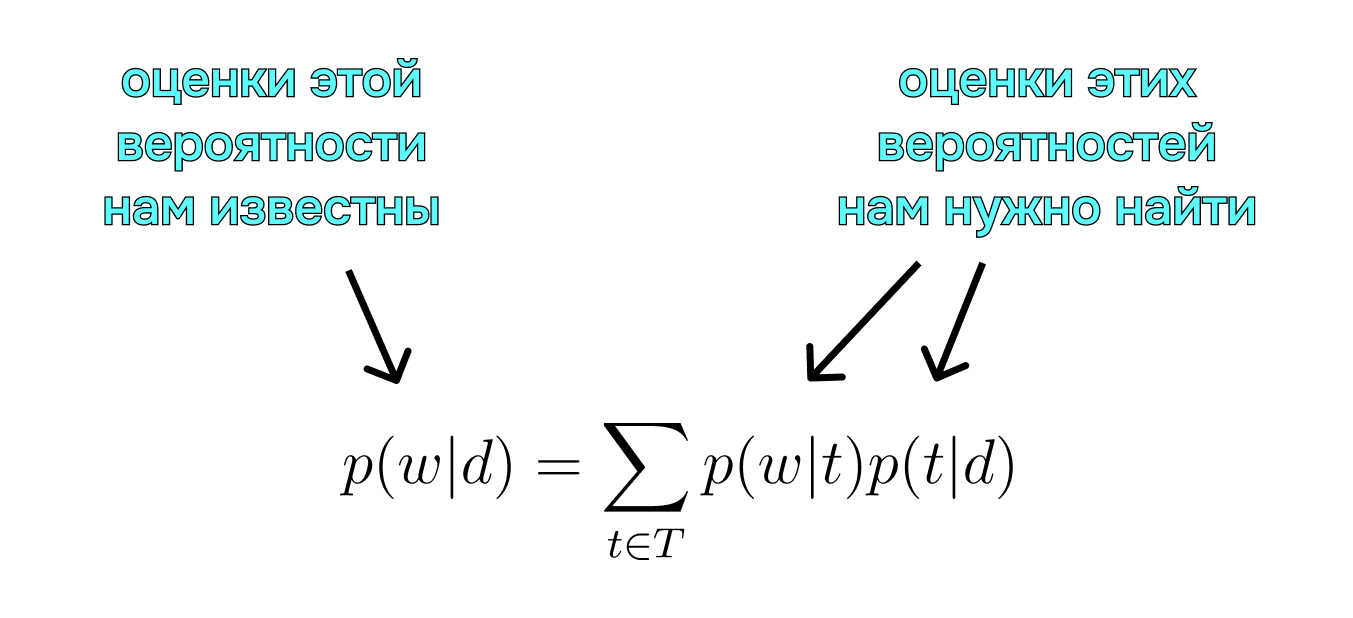
p(w|t) и p(t|d), то с их помощью мы могли бы восстанавливать p(w|d), то есть генерировать текст, взвешенно-случайно выбирая для каждого текста сначала темы, а потом слова из этих тем. 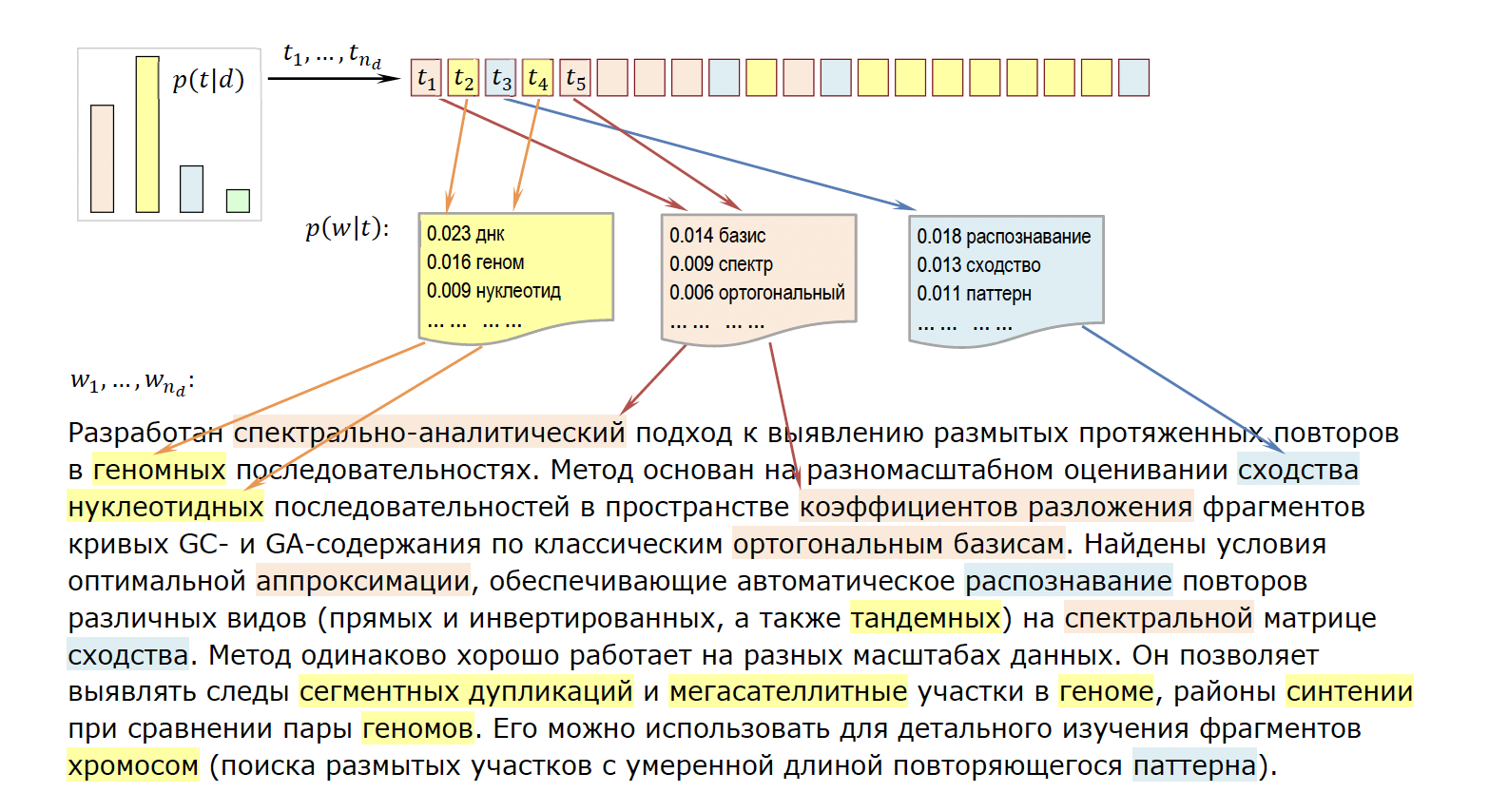
Классические модели: PLSA и LDA
Внимательный читатель, знакомый с математикой и теорией машинного обучения, посмотрев на предыдущий раздел, скажет: “Тут же сама собой напрашивается оптимизационная задача максимизации правдоподобия!” – и окажется прав. Действительно, то самое равенство, которое мы видели в прошлой главе, на самом деле ведет нас к такой задаче математического программирования:  На этом месте у нас есть две новости, хорошая и плохая. Плохая: эта задача поставлена некорректно по Адамару, потому что существует бесконечное множество ее решений. Хорошая: это можно легко обойти, применив регуляризацию. Многие из нас, скорее всего, неоднократно встречались с L1 или L2 регуляризацией. Эти методы применяются для того, чтобы каким-то образом ограничить множество решений дополнительными критериями. В задаче тематического моделирования регуляризации используются с той же целью и помогают найти единственное устойчивое решение задачи выше. На практике регуляризаторы могут помогать учитывать нетекстовые данные, улучшать качество классификации текстов, точность и полноту поиска, различность тем, разреженность решения и т.д.
На этом месте у нас есть две новости, хорошая и плохая. Плохая: эта задача поставлена некорректно по Адамару, потому что существует бесконечное множество ее решений. Хорошая: это можно легко обойти, применив регуляризацию. Многие из нас, скорее всего, неоднократно встречались с L1 или L2 регуляризацией. Эти методы применяются для того, чтобы каким-то образом ограничить множество решений дополнительными критериями. В задаче тематического моделирования регуляризации используются с той же целью и помогают найти единственное устойчивое решение задачи выше. На практике регуляризаторы могут помогать учитывать нетекстовые данные, улучшать качество классификации текстов, точность и полноту поиска, различность тем, разреженность решения и т.д.
И еще одна хорошая новость: в тематическом моделировании, вне зависимости от того, какие именно регуляризаторы мы используем, можно выработать единый общий рецепт решения. Но об этом – немного позже.
Самой цитируемой и известной моделью в тематическом моделировании можно назвать модель LDA (latent Dirichlet allocation) – латентное размещения Дирихле. Она была изобретена в 2003 году. Ей предшествовала более простая модель вероятностного латентного семантического анализа, PLSA (1999), которая решала задачу без регуляризаторов вообще или, говоря точнее, просто находила какое-то одно решение из бесконечного множества.
LDA же была первой моделью, в которую исследователи смогли поместить регуляризацию, но, к сожалению, самую простую и только одну. В основе LDA – байесовское обучение: мы задаем априорное распределение на наши параметры модели или, вернее сказать, на матрицы φ и θ , далее добавляем в модель некоторые данные и получаем апостериорные распределения. Этот метод нетривиален — приходится формировать сложные математические выкладки и, если вам захочется добавить какое-то новое ограничение на матрицы φ и θ (то есть новый регуляризатор), это потребует уникального подхода и долгой и непростой теоретической работы, и мы уже не говорим про софт.
 15 лет тематическое моделирование продолжало развиваться в рамках такого байесовского подхода: за эти годы были придумано несколько сотен, а может, даже тысяч моделей с разными регуляризаторами, но изящно объединять их так никто и не научился. Пока в 2014 году Константин Воронцов и Анна Потапенко не придумали ARTM.
15 лет тематическое моделирование продолжало развиваться в рамках такого байесовского подхода: за эти годы были придумано несколько сотен, а может, даже тысяч моделей с разными регуляризаторами, но изящно объединять их так никто и не научился. Пока в 2014 году Константин Воронцов и Анна Потапенко не придумали ARTM.
ARTM
Подчеркнем, что ARTM не является еще одной моделью или методом — это общий подход к построению и комбинированию любых тематических моделей. Расшифровывается аббревиатура как Аддитивная регуляризация тематических моделей. Аддитивной она называется потому, что вместо того, чтобы для каждого регуляризатора придумать отдельные математические трюки, мы просто представляем его в виде некоторого функционала и прибавляем к основной функции оптимизации, которая максимизирует правдоподобие.
Получается, что в данном случае нам вообще неважно, сколько у нас регуляризаторов и насколько они сложные: на нашей задаче это отражается только в виде дополнительного слагаемого с некоторым весом. В машинном обучении такой подход называется мультизадачным обучением (multitask learning).
Теперь, когда нам не нужно отдельно работать над каждым регуляризатором, можно каждый раз пользоваться одним и тем же методом решения задачи. А именно, оказывается, что ее решение сводится к решению некоторой системы уравнений, называемой также EM-алгоритмом.  E-шаг здесь – это вычисление условных распределений скрытых переменных по формуле Байеса. А M-шаг – от слова maximization, вычисление самих параметров модели. Это итерационный алгоритм, то есть сначала здесь выбираются начальные приближения параметров
E-шаг здесь – это вычисление условных распределений скрытых переменных по формуле Байеса. А M-шаг – от слова maximization, вычисление самих параметров модели. Это итерационный алгоритм, то есть сначала здесь выбираются начальные приближения параметров φ и θ, а затем по ним вычисляются вспомогательные переменные p_tdw, которые в свою очередь позволяют найти следующее приближение параметров φ и θ.
Кстати, при таком взгляде на вещи ранее рассмотренные нами модели PLSA и LDA оказываются просто частными случаями обобщенной задачи.
Как мы уже упоминали, ARTM появилась в 2014 году. Тогда же стартовал проект BigARTM, который воплотил в себе идеи аддитивной регуляризации и расширил спектр приложений тематического моделирования, сняв многие ограничения простых моделей типа PLSA или LDA. Сейчас мы на практике разберемся в этой библиотеке подробнее.
К практике
BigARTM – это библиотека с открытым исходным кодом, самый быстрый инструмент для тематического моделирования. BigARTM бодрее даже аналогичных реализаций в широко известных Gensim и Vowpal Wabbit. При этом в библиотеке реализован очень широкий спектр полезных механизмов:
- Regularization. Регуляризаторы, которые можно комбинировать в любых сочетаниях.
- Modalities. Модальности, которыми можно описывать нетекстовые объекты внутри документов.
- Hierarchy. Тематические иерархии, в которых темы разделяются на подтемы.
- Co-occurrence. Использование данных о совместной встречаемости слов.
- Intratext. Внутритекстовые регуляризаторы, обрабатывающие текст как последовательность тематических векторов слов. Они позволяют учитывать порядок слов, синтаксические связи, деление текста по предложениям и абзацам и другую внутритекстовую информацию.
- Transaction. Тематизация транзакционных данных. Транзакциями называются взаимодействия между объектами. Примером транзакции в тексте является вхождение слова в документ или появление пары слов в общем контексте. Предложения, фразы или словосочетания также являются примерами текстовых транзакций.

Кстати, Big в названии не значит “много кода”. Просто библиотека позволяет обрабатывать большие объемы данных. Вот некоторые технические подробности того, как это реализовано:
- Распараллеливание на ядрах центрального процессора;
- Пакетная обработка данных, не требующая единовременной загрузки больших данных в оперативную память;
- Эффективный алгоритм с линейной вычислительной сложностью по объему коллекции и по числу тем;
- Хранение самых часто обновляемых данных – распределений слов в темах – целиком в оперативной памяти;
- Реализация ядра библиотеки на языке С++ соблюдением современных стандартов промышленного программирования.
Библиотека является кроссплатформенной: сборку и исполнение можно производить под Windows 7/8/10, Mac OS и различными дистрибутивами Linux. Поддерживаются программные интерфейсы под Python 2.7.*/3.*, C++, а также запуск в виде исполняемого бинарного файла. Детальную информацию о библиотеке можно найти в документации на сайте http://bigartm.org.
Сейчас мы вместе с BigARTM пройдемся по пути построения тематической модели. Первое, что нам понадобится – это подготовить данные. Если ваша коллекция не слишком большая, то сделать это можно очень просто, с помощью sklearn:
# Import all necessary tools and data
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.datasets import fetch_20newsgroups
from numpy import array
import artm
# Extract data using sklearn and numpy
cv = CountVectorizer(max_features=1000, stop_words=’english’)
n_wd = array(cv.fit_transform(fetch_20newsgroups().data).todense()).T
vocabulary = cv.get_feature_names()
# Create batches and dictionary
bv = artm.BatchVectorizer(data_format=’bow_n_wd’,
n_wd=n_wd,
vocabulary=vocabulary)
В коде наверху вы видите объект класса artm.BatchVectorizer. Это векторизатор – универсальный объект, принимаемый на вход всеми операциями BigARTM. В примере выше он был создан по матрице мешка слов n_wd и словаря, задающего соответствие между строками матрицы и словами коллекции. Если же ваши данные уже предобработаны и хранятся в UCI формате, то векторизатор можно создать так:
batch_vectorizer = artm.BatchVectorizer(data_path=' ',
data_format='bow_uci',
collection_name='my_collection',
target_folder='my_collection_batches')
Кроме векторизатора стоит также создать словарь. Словари BigARTM предназначены для хранения данных о словах и используются в некоторых регуляризаторах и метриках качества. Словарю соответствует объект artm.Dictionary, который можно либо сформировать автоматически во время разбиения коллекции на пакеты (задав в artm.BatchVectorizer параметр gather_dictionary, по умолчанию равный True), либо создать вручную на основе своих данных.
bv.dictionary.save(’my_collection_batches/dictionary’)
# Load dictionary back during next BigARTM launch:
dictionary = artm.Dictionary()
dictionary.load(’my_collection_batches/dictionary.dict’)
На этом тему предобработки можно считать закрытой, и мы переходим к модели. Пайплайн создания и обучения модели в BigARTM очень напоминает аналогичный пайплайн в sklearn, так что опытному Data Scientist’у последующий интерфейс покажется очень привычным. Для начала нужно просто определить объект модели и задать желаемое количество тем:
model = artm.ARTM(num_topics=15, dictionary=bv.dictionary)
По сути, на этом шаге происходит создание матрицы параметров φ размером (количество слов в вашем словаре) x (количество тем). Эта матрица инициализируется случайным образом. Теперь наша цель – обучить созданную модель. Для этого для начала нужно задать ей метрики. Для этого удобно использовать подкласс scores класса ARTM. Например, вот так можно добавить в модель метрику перплексии:
model.scores.add(artm.PerplexityScore(name='my_first_perplexity_score',
dictionary=my_dictionary))
Кроме перплексии, в библиотеке можно также найти такие метрики, как разреженность матриц, чистота, контранстность, когерентность и доля фоновых слов. 
model.fit_offline(batch_vectorizer=batch_vectorizer, num_collection_passes=10)
Эта строка кода – первый шаг обучения. После него стоит посмотреть на метрики и убедиться, что все в порядке. Сделать это можно так:
print model.score_tracker['my_fisrt_perplexity_score'].value
После этого обучение мы можем продолжить:
model.fit_offline(batch_vectorizer=batch_vectorizer, num_collection_passes=15)
И так далее. Кстати, если в какой-то момент вы поймете, что ваша модель выродилась, то создавать новую не обязательно. Достаточно вызвать model.initialize(dictionary=my_dictionary) и матрица параметров снова вернется к исходному состоянию случайной инициализации.
Ну вот мы и обучили нашу первую тематическую модель. Однако внимательный читатель уже заметил, что мы ни разу не упомянули и не использовали регуляризацию, о которой так много говорили в предыдущих частях статьи. Напоминаем, что регуляризаторы нужны нам для того, чтобы некоторым образом воздействовать на матрицы параметров. В BigARTM уже реализованы очень многие наиболее полезные регуляризаторы:
- Сглаживание заставляет распределение слов в теме (или распределение тем в документе) быть похожим на заданное распределение. Это аналог модели LDA.
- Разреживание обнуляет малые вероятности в распределении слов в теме (или в распределении тем в документе).
- Декоррелирование делает темы более различными.
- Отбор тем позволяет модели избавляться от мелких, неинформативных, дублирующих и зависимых тем.
- Когерентность группирует часто совместно встречающиеся слова в одних и тех же темах, улучшая интерпретируемость тем.
Подробнее обо всех регуляризаторах BigARTM можно прочитать здесь. Что касается кода, то добавить регуляризатор в модель очень просто. Нужно просто вызвать model.regularizers.add:
model.regularizers.add(artm.SmoothSparsePhiRegularizer(
name='sparse_phi_regularizer')
)
model.regularizers.add(artm.SmoothSparseThetaRegularizer(
name='sparse_theta_regularizer')
)
model.regularizers.add(artm.DecorrelatorPhiRegularizer(
name='decorrelator_phi_regularizer')
)
Регуляризаторы могут включаться, отключаться или модифицироваться в любой момент между вызовами fit_offline или fit_online, что позволяет, в совокупности с контролем метрик качества, гибко перестраивать стратегию регуляризации в соответствии с текущим состоянием модели. Вот пример того, как этим можно пользоваться:
reg = artm.DecorrelatorPhiRegularizer(name=’decor’, tau=1e+5)
model.regularizer.add(reg)
model.scores.SparsityPhiScore(name=’sparse’)
model.fit_offline(batch_vectorizer=bv, num_collection_passes=10)
print model.score_tracker(’sparse’).last_value
# Printing result: 0.15 - too small. Let’s increase tau
model.regularizer[’decor’].tau = 3e+5
model.fit_offline(batch_vectorizer=bv, num_collection_passes=15)
Регуляризаторы подобны лекарствам: в малых дозах они бесполезны, в больших становятся ядом, а некоторые их сочетания приводят к плохо предсказуемым последствиям. Поэтому комбинирование регуляризаторов требует проведения экспериментов по подбору коэффициентов, управляющих силой их воздействия на модель. Обычно их включают по очереди, подбирая для каждого коэффициент регуляризации «методом проб и ошибок».
Но и это не все. В BigARTM можно обрабатывать документы, содержащие не только слова, но и токены других модальностей. Это могут быть какие-то метаданные документов или что-то, содержащееся внутри них: ссылки, картинки, именованные сущности и др. Модальности помогают строить темы с учетом дополнительной информации. С другой стороны, темы помогают выявлять семантику нетекстовых модальностей, предсказывать или рекомендовать значения пропущенных токенов.

Следующий шаг — донести до вашей модели информацию о ваших модальностях и их важности. Для этого используйте примерно такой код:
model = artm.ARTM(num_topics=20, class_ids={'@default_class': 1.0, '@labels_class': 5.0})
Мы только что создали мультимодальную модель с двумя модальностями, при этом модальность меток классов будет для нее важнее, чем токены модальности @default_class. Веса модальностей, к слову, тоже можно менять между эпохами обучения.
Что касается регуляризаторов, то стоит обратить внимание на то, что пользователь может самостоятельно настроить, с какими модальностями и как будет работать каждый из них. В остальном, обучение мультимодальной тематической модели ничем не отличается от обычного пайплайна обучения, который мы рассматривали ранее.
Заключение
На этом наше путешествие по тематическому моделированию и библиотеке BigARTM подходит к концу. В статье мы рассмотрели математическую и интуитивную постановку задачи тематического моделирования, классические подходы к ее решению и алгоритм ARTM, а также практический подход к построению классической и мультимодальной тематической модели в библиотеке BigARTM.
Чтобы разобраться с деталями задачи тематического моделирования еще лучше, советуем прочитать это пособие Константина Вячеславовича по тематическому моделированию на русском языке. А больше информации и гайдов по библиотеке BigARTM можно найти в документации.
