
Недавно на Kaggle был запущен конкурс AI Mathematical Olympiad, участники которого пробуют заставить LLM модели решать олимпиадные математические задачи старших классов на уровне человека. Тому, кто сделает это лучше всего, достанется 1 миллион долларов. В конкурсе принимают участие уже более 800 человек. Если заглянуть в раздел Code, то мы увидим множество решений, основанных на предобученных моделях. Среди них можно особенно часто встречается так называемая DeepSeekMath.
 DeepSeekMath – это модель, разработанная исследователями из китайской лаборатории DeepSeek в начале 2024 года. Она достигает поразительного результата в 51.7% на бенчмарке MATH, не уступая уровню сильнейших закрытых Gemini-Ultra и GPT-4.
DeepSeekMath – это модель, разработанная исследователями из китайской лаборатории DeepSeek в начале 2024 года. Она достигает поразительного результата в 51.7% на бенчмарке MATH, не уступая уровню сильнейших закрытых Gemini-Ultra и GPT-4.  Секрет успеха DeepSeekMath в основном заключается в изящной работе с данными, но не только это в работе интересно. Также исследователи предложили собственный алгоритм обучения с подкреплением – Group Relative Policy Optimization, основанный на классическом Proximal Policy Optimization.
Секрет успеха DeepSeekMath в основном заключается в изящной работе с данными, но не только это в работе интересно. Также исследователи предложили собственный алгоритм обучения с подкреплением – Group Relative Policy Optimization, основанный на классическом Proximal Policy Optimization.
Итак, эта статья – краткое и понятное изложение основных идей DeepSeekMath, которое поможет вам разобраться с еще одной интересной архитектурой и, возможно, выиграть миллион долларов :)
Сбор корпуса данных
Летом не столь далекого 2022 года Google также приложила немало усилий к тому, чтобы научить LM понимать математику. Они разработали Minerva, которая стала настоящей сенсацией, на тот момент обогнав все существующие решения. Ученые попробовали множества разных подходов, но основной вывод оказался таким: дело, в основном, в данных. Их должно быть много, они должны быть разнообразные и чистые.
DeepSeek приняли выводы коллег к сведению и также сосредоточились на данных. До этого классическими для обучения таких математических моделей считались три датасета: MathPile, OpenWebMath и Proof-Pile-2. Все они показались исследователям недостаточно большими и разнообразными, поэтому было принято решение собрать свой собственный корпус DeepSeekMath Corpus.
Для этого авторы предложили изящный итеративный пайплайн. В качестве исходного мат.датасета был выбран OpenWebMath. Целью было обогатить его связанными с математикой веб-страницами. Веб-страницы брались из известного корпуса данных Common Crawl, который содержит неразмеченные данные с миллионов Интернет-сайтов. Итак, пайплайн:
- Обучение классификатора FastText для распознания веб-страниц, связанных с математикой. В качестве положительных образцов принимались мат.данные из исходного датасета OpenWebMath (seed), в качестве негативных образцов случайно выбирались 500 тысяч наблюдений из Common Crawl.
- Прогон Common Crawl через обученный классификатор. На этом шаге мы отбираем из Common Crawl те страницы, которые наш FastText счёл связанными с математикой. Однако берем из них не все, а только топ самых вероятных, чтобы наш корпус получился чистым. Удаляем дубликаты.
- Отбор Интернет-доменов, которые целиком относятся к математике. Домен считается таковым, если более 10% веб-страниц в нем классификатор определил, как математические. Такие домены затем обрабатывались вручную.
- Добавление всех URL из пункта 2 и URL, относящихся к доменам из пункта 3, в корпус OpenWebMath. На этом шаге происходит то самое обогащение seed корпуса, который далее участвует в следующей итерации.
- Возвращаемся к пункту 1 и снова учим классификатор, теперь на большем количестве данных. Таким образом, раз за разом обогащая датасет, мы увеличиваем точность классификатора, что в свою очередь позволяет найти еще больше данных. И так по кругу.
 Чтобы собрать итоговый DeepSeekMath Corpus, таких циклов понадобилось четыре. На четвертой итерации оказалось, что 98% из получившихся данных уже были собраны на третьей итерации, а классификатор больше не показывает значительного прироста в качестве, поэтому процесс был прерван.
Чтобы собрать итоговый DeepSeekMath Corpus, таких циклов понадобилось четыре. На четвертой итерации оказалось, что 98% из получившихся данных уже были собраны на третьей итерации, а классификатор больше не показывает значительного прироста в качестве, поэтому процесс был прерван.
Чтобы сравнить свой корпус с другими, исследователи поступили просто: натренировали абсолютно идентичные архитектуры на равном количестве данных из разных датасетов и посмотрели на их качество. Оказалось, что модели, обученные на DeepSeekMath Corpus по банчмаркам значительно превзошли те, которые обучались на данных из MathPile, OpenWebMath и Proof-Pile-2.
 Кроме того, оказалось, что на DeepSeekMath Corpus модели учатся качественнее и быстрее: обратите внимание, насколько более круто по сравнению с другими кривыми красная, соответствующая DeepSeekMath Corpus, уходит вверх.
Кроме того, оказалось, что на DeepSeekMath Corpus модели учатся качественнее и быстрее: обратите внимание, насколько более круто по сравнению с другими кривыми красная, соответствующая DeepSeekMath Corpus, уходит вверх.
 Итак, в итоге мы получаем большой, разнообразный и чистый датасет. Стоит упомянуть, что такой итеративный подход может быть использован для сбора данных и в других областях: например, в программировании или медицине.
Итак, в итоге мы получаем большой, разнообразный и чистый датасет. Стоит упомянуть, что такой итеративный подход может быть использован для сбора данных и в других областях: например, в программировании или медицине.
Пре-трейн
Тут нужно упомянуть, что за некоторое время до выпуска модели DeepSeekMath у той же лаборатории вышла в двух размерах не менее качественная модель DeepSeekCoder, заточенная под задачи по программированию.
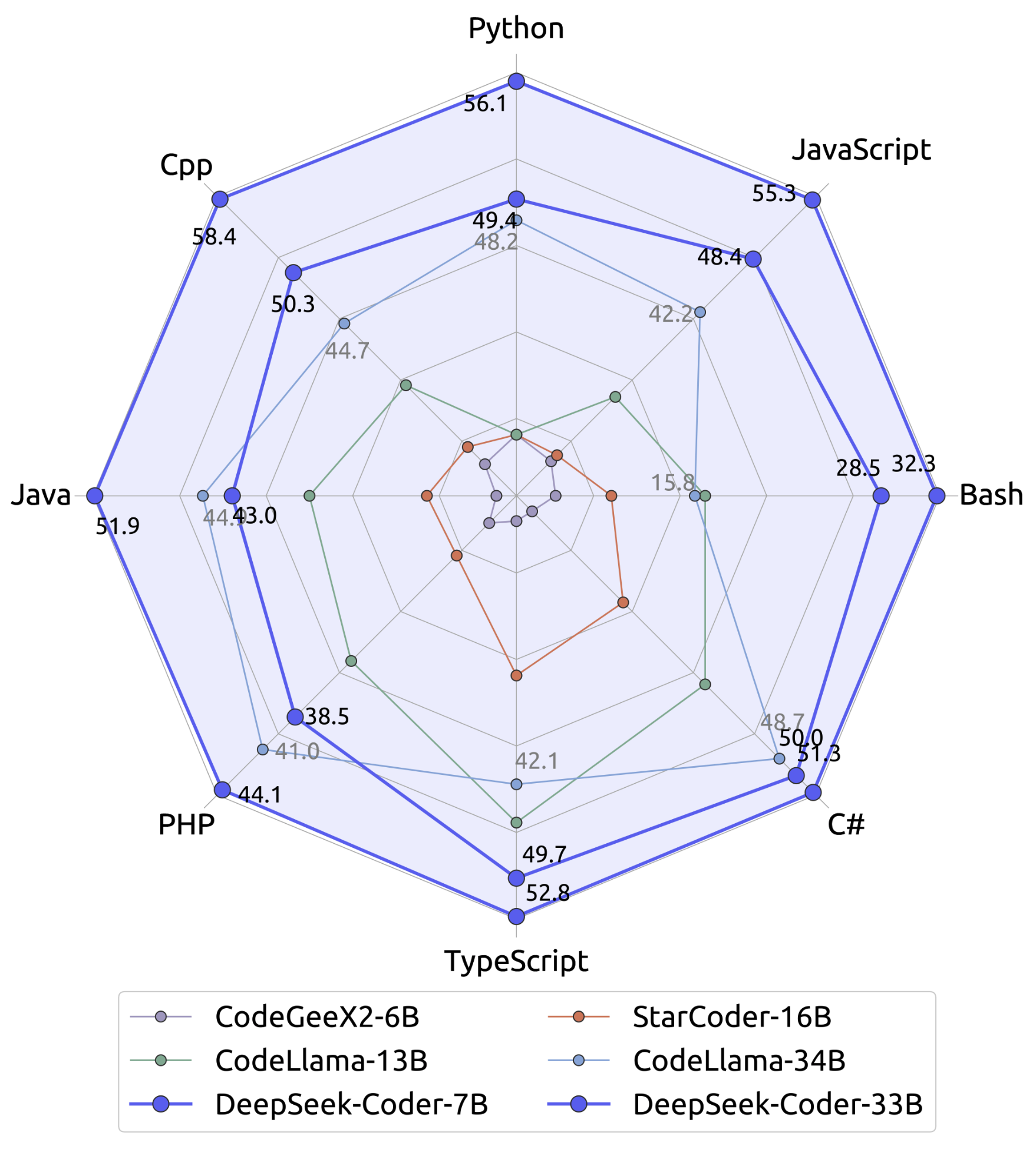 Эту модель, а именно DeepSeek-Coder-Base-v1.5 7B, исследователи использовали для инициализации DeepSeekMath-Base 7B. Под инициализацией подразумевается начальная установка весов модели. Далее DeepSeekMath-Base 7B обучали на 500В токенов: 56% взяли из только что рассмотренного нами корпуса DeepSeekMath Corpus, 4% из AlgebraicStack, 10% из статей с arXiv, 20% – Github, 10% – обычный Common Crawl. Последнее добавили, чтобы модель не растеряла способности понимать обычный текст и письменную речь пользователя.
Эту модель, а именно DeepSeek-Coder-Base-v1.5 7B, исследователи использовали для инициализации DeepSeekMath-Base 7B. Под инициализацией подразумевается начальная установка весов модели. Далее DeepSeekMath-Base 7B обучали на 500В токенов: 56% взяли из только что рассмотренного нами корпуса DeepSeekMath Corpus, 4% из AlgebraicStack, 10% из статей с arXiv, 20% – Github, 10% – обычный Common Crawl. Последнее добавили, чтобы модель не растеряла способности понимать обычный текст и письменную речь пользователя.
Качество не разочаровало: и на английских, и на китайских бенчмарках модель показала себя даже лучше, чем Minerva и Llemma большего размера.
 А когда ученые "разрешили" модели при решении задач использовать Python, качество подскочило еще больше, обогнав даже CodeLlama 34В:
А когда ученые "разрешили" модели при решении задач использовать Python, качество подскочило еще больше, обогнав даже CodeLlama 34В:
 Дополнительно исследователи выяснили интересную вещь: модель, обученная решать задачи по программированию, лучше решает математические задачи.
Дополнительно исследователи выяснили интересную вещь: модель, обученная решать задачи по программированию, лучше решает математические задачи.  В таблице видно, что если сначала обучить обычную LM, а затем скормить ей математические данные, то она будет гораздо "глупее", чем модель, которая перед математикой обучалась программированию.
В таблице видно, что если сначала обучить обычную LM, а затем скормить ей математические данные, то она будет гораздо "глупее", чем модель, которая перед математикой обучалась программированию.
Файн-тюнинг
Base model, которую мы рассмотрели в предыдущей части, это еще не все. Как вы заметили, base model училась просто на математическом тексте, другими словами изучала не то, как правильно отвечать на вопросы, а скорее учила общие закономерности и языковые структуры. Она тоже способна отвечать на вопросы, но ответы могут быть размытыми и нечеткими.
Чтобы улучшить способность модели следовать конкретным инструкциям и выполнять специализированные задачи, к Base модели применяется файнтюнинг – дообучение на данных, содержащих уже не просто текст, а конкретные примеры вопросов и ответов. Такая модель оптимизирована для взаимодействия с пользователем и выполнения задач по команде.
И снова в случае с DeepSeekMath ученые уделили основное внимание данным для файнтюнинга. Они не просто взяли обучающую выборку вида "вопрос-ответ" из бенчмарков, а добавили в каждый пример, помимо вопроса, решение – это называется chain-of-thought (CoT) и program-of-thought (PoT). Это нужно было для того, чтобы модель не просто топорно давала ответ на задачу, а умела объяснять, как она его получила. Сравните: 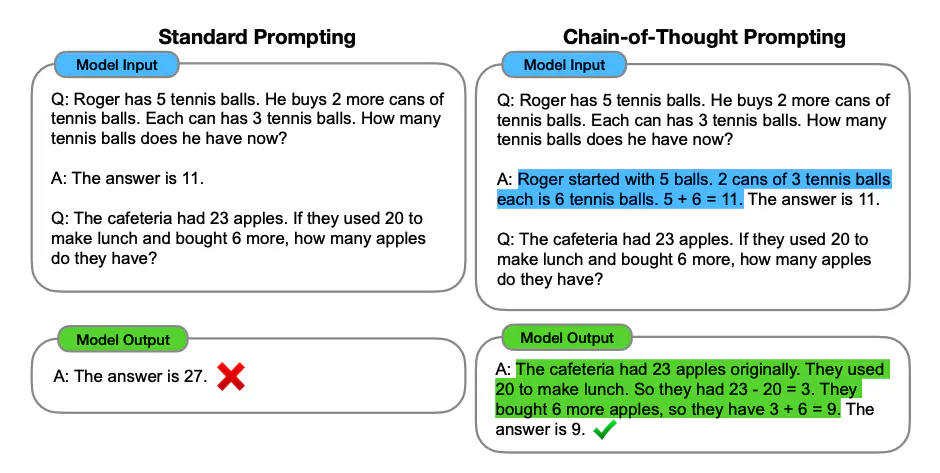 Вопросы в выборку были включены на разные темы: алгебра, теория вероятностей, теория чисел, мат.анализ, геометрия.
Вопросы в выборку были включены на разные темы: алгебра, теория вероятностей, теория чисел, мат.анализ, геометрия.  Получившаяся модель DeepSeekMath-Instruct 7B отлично показывает себя даже в сравнении с GPT-4 и Gemini Ultra/Pro, не говоря уже об опенсорс моделях большего размера.
Получившаяся модель DeepSeekMath-Instruct 7B отлично показывает себя даже в сравнении с GPT-4 и Gemini Ultra/Pro, не говоря уже об опенсорс моделях большего размера.
Обучение с подкреплением
Если внимательно присмотреться к предыдущей таблице, то помимо DeepSeekMath-Instruct вы увидите DeepSeekMath-RL, которая показывает еще более высокие результаты. Эта модель получается посредством применения к DeepSeekMath-Instruct обучения с подкреплением (RL). Как известно, на один и тот же вопрос модель может из раза в раз отвечать по-разному, и какие-то ее ответы могут быть лучше, а другие хуже. RL не улучшает базовые способности модели, но как раз учит ее "выбирать" наиболее подходящие пользователю варианты ее ответов. Формально говоря, цель RL – сделать распределение выходных данных более надежным.
Разберемся, как это происходит. Вообще, обучение с подкреплением – это метод обучения, при котором агент (в нашем случае модель) учится принимать решения, взаимодействуя с окружающей средой. Агент получает награды за свои действия и стремится максимизировать общую награду. На каждом шаге взаимодействия со средой у агента есть политика – стратегия, которой следует агент, определяющая, какое действие он должен предпринять в каждом состоянии.
Самым распространенным для языковых моделей алгоритмом RL является Proximal Policy Optimization (PPO). Его суть:
- У агента есть начальная политика (стратегия), по которой она действует.
- Агент выполняет действия в среде (отвечает на вопросы), следуя своей текущей политике
- PPO оценивает действие модели. Для этого обычно используется три модели: reference model – модель, которая выступает "эталоном" для сравнения, reward model – оценивает награду, которую агент получает за выполнение конкретного действия в конкретном состоянии, value model – оценивает ожидаемую долгосрочную выгоду от действия, предсказывая будущие награды.
- На основе этих оценок агент меняет свою политику. Здесь заключена основная особенность алгоритма: функция потерь в PPO устроена так, что слишком резкие изменения политики не допускаются. Это помогает агенту постепенно улучшать свою стратегию, не делая слишком больших шагов сразу, что делает процесс обучения более стабильным и эффективным.
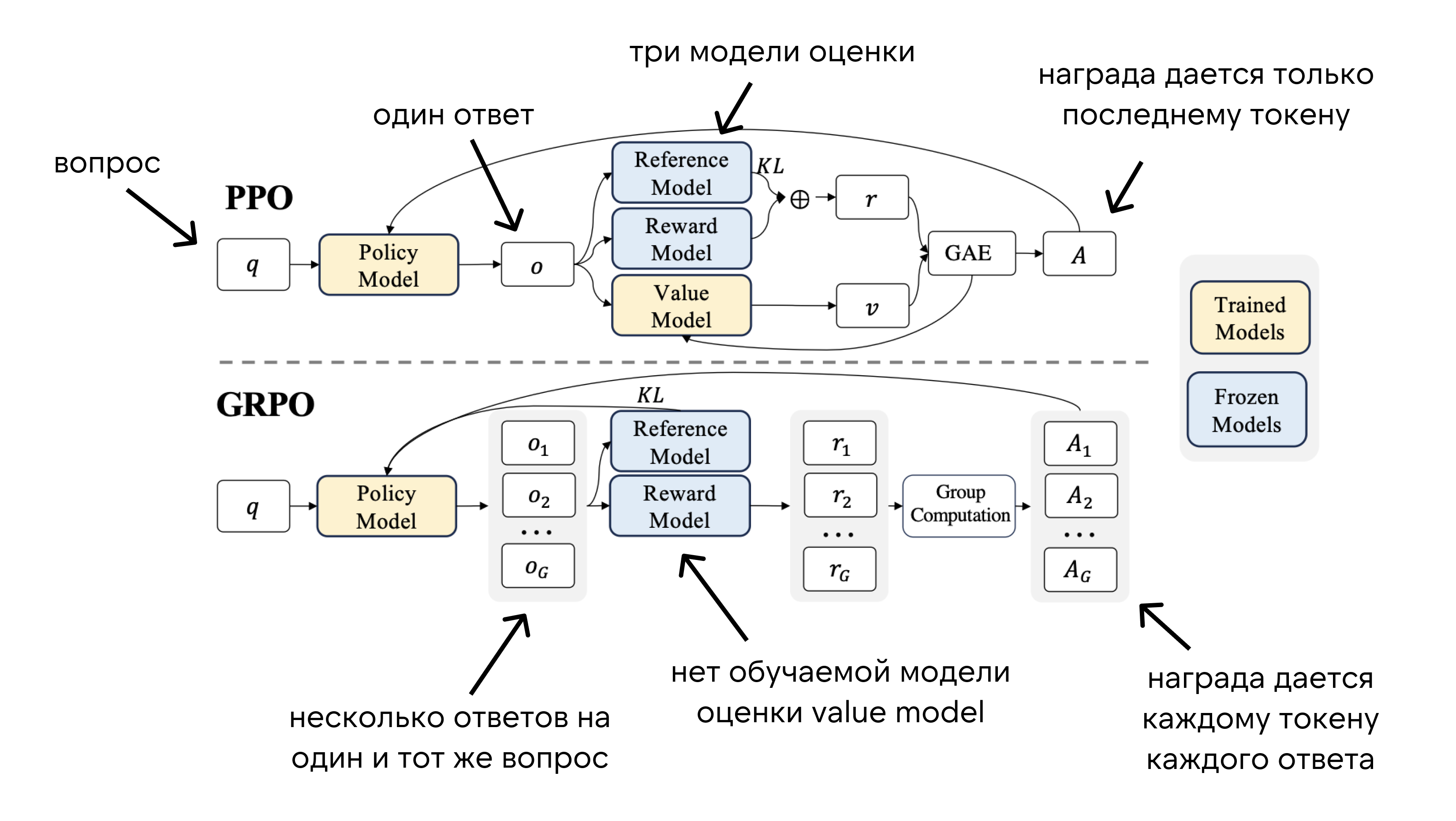
Взяв этот алгоритм за основу, авторы DeepSeekMath предложили небольшую его модификацию – Group Relative Policy Optimization (GRPO). Во-первых, из алгоритма PPO выкинули value model, которая, в отличие от других моделей оценки, требует обучения и потребляет из-за этого много ресурсов и памяти. Вместо value model в GRPO мы используем среднюю награду от группы ответов на один и тот же вопрос, чтобы определить, насколько хороши действия модели. Это компенсирует оценку value model и делает обучение более эффективным и менее ресурсоемким.
 Результат: обученная с помощью GRPO DeepSeekMath-RL 7B достигает точности 88,2% и 51,7% в GSM8K и MATH соответственно. Эта производительность превосходит показатели всех моделей с открытым исходным кодом в диапазоне от 7B до 70B, а также большинства моделей с закрытым исходным кодом.
Результат: обученная с помощью GRPO DeepSeekMath-RL 7B достигает точности 88,2% и 51,7% в GSM8K и MATH соответственно. Эта производительность превосходит показатели всех моделей с открытым исходным кодом в диапазоне от 7B до 70B, а также большинства моделей с закрытым исходным кодом.
Итог
Итак, еще раз пройдемся по основным фичам, из которых сделана DeepSeekMath:
- Итеративный сбор собственного большого, разнообразного и чистого корпуса данных для пре-трейна
- Пре-трейн с инициализацией на модели DeepSeek-Coder-v1.5 7B
- Файнтюнинг на chain-of-thought (CoT) и program-of-thought (PoT)
- Обучение с подкреплением на базе собственного алгоритма GRPO – вариации PPO
В итоге из этих "кирпичиков" получилась модель, которая превосходит все модели с открытым исходным кодом на бенчмарке MATH и приближается к производительности закрытых моделей. На этом, кстати, подвижки ученых из DeepSeek в сторону математики не прекратились: модель постоянно обновляется, также как и статья, а также исследователи продолжают работать над сбором качественных данных и алгоритмами RL.
Надеемся, этот разбор вам понравился! Заглядывайте к нам чаще, чтобы не пропускать свежие статьи и новости.